 崱擔偺昁偢僩僋偡傞堦尵
崱擔偺昁偢僩僋偡傞堦尵-- TODAY'S REMARK --
崱擔偺昁偢僩僋偡傞堦尵 Version March 1998
Version March 1998
March 31
 俥捠偺婼偭巕儅僔儞MV205偺僫僝乮崱帪AT儅僓乕儃乕僪嵦梡曇乯
俥捠偺婼偭巕儅僔儞MV205偺僫僝乮崱帪AT儅僓乕儃乕僪嵦梡曇乯
March 28
僨儕僶僥傿僽庢堷偺僫僝
March 25
CPU儊儌儕乕揮憲擻椡偺僫僝嵟廔曇乮Pentium-2,P55C,
K6,CyrixMMX傪摨僋儘僢僋偱斾傋傞曇)
March 20
PPP愙懕傪儘僴偱崅懍壔偡傞曽朄偺僫僝偦偺俀(嶳杮幃僽儘僢僋儌乕僪愝掕偱偁偲15%壱偖曇)
March 14
PPP愙懕傪儘僴偱崅懍壔偡傞曽朄偺僫僝(tcp/ip偲Ethernet偺杮幙偵敆傞曇)
March 9
僟儊側儅僂僗偺僫僝(僱僢僩巎忋弶丄嶳杮幃儅僂僗夵憿朄儕傾儖價僨僆曇)
March 7
嶳杮幃僶乕僠儍儖僒僂儞僪僔僗僥儉(PAT
PEND.)偺僫僝
March 5
暯惉10擭宆愇桘僼傽儞僸乕僞乕偺僫僝乮婫愡抶傟偺僱僞曇乯
March 3
俴俀僉儍僢僔儏桳岠偱儀儞僠儅乕僋偑抶偔側傞CPU偺僫僝乮6x86MX偲P55C偺堘偄傪扵傞曇乯
March 1
嶳杮幃僗乕僷乕僗儘僢僩僗僞價儔僀僓乕偺僫僝乮晽悈妛揑僲僀僘媦傃揹埑崀壓崻愨曇乯
俥捠偺婼偭巕儅僔儞MV205偺僫僝乮崱帪AT儅僓乕儃乕僪嵦梡曇乯
嵟嬤俥捠偐傜MV205側傞曄側儅僔儞偑弌偨偺偱挷払偟偨乮幨恀偼俥捠偺儕儞僋乯丅傑偢奿岲偑僿儞偩丅崱帪埨暔偼僨僗僋僩僢僾丄崅媺昳偼儈僪儖僞儚乕偑庡棳偩偑丄偙傟偼埨暔側偺偵儅僀僋儘僞儚乕偩丅慜柺僷僱儖壓曽偲働乕僗懁柺偵捠晽岥偑偁傞偺偱捠晽偼椙偄丅儅僓乕偼働乕僗偲暿懱偺斅偵屌掕偝傟偰偄傞丅
 儅僀僋儘僞儚乕偲徧偟偰偄傞偑丄幚嵺偵偼AT儈僯僞儚乕偵憡摉偡傞丅僪儔僀僽儀僀偼5inchx2丄3.5inchx3偱丄偆偪俁偮偑婄傪弌偟3.5inchx2偑嬻偄偰偄傞丅偙偺働乕僗偼ACER偺OEM傪俥捠偑夵埆偟偰偄傞丅ACER弮惓働乕僗偱偼3.5inch偑俀屄僷僱儖偵婄傪弌偟偰偄傞偺偵丄俥捠偼侾屄偺傒丅斅嬥晹暘偼俀偮暘嬻偄偰偄傞偺偵偱偁傞丅偍偦傜偔儔僀儞傾僢僾偺惍崌惈傪庢傞偨傔偩傠偆偑丄傑偭偨偔梋寁側帠傪偟偰偔傟傞傕傫偩丅埲慜丄
儅僀僋儘僞儚乕偲徧偟偰偄傞偑丄幚嵺偵偼AT儈僯僞儚乕偵憡摉偡傞丅僪儔僀僽儀僀偼5inchx2丄3.5inchx3偱丄偆偪俁偮偑婄傪弌偟3.5inchx2偑嬻偄偰偄傞丅偙偺働乕僗偼ACER偺OEM傪俥捠偑夵埆偟偰偄傞丅ACER弮惓働乕僗偱偼3.5inch偑俀屄僷僱儖偵婄傪弌偟偰偄傞偺偵丄俥捠偼侾屄偺傒丅斅嬥晹暘偼俀偮暘嬻偄偰偄傞偺偵偱偁傞丅偍偦傜偔儔僀儞傾僢僾偺惍崌惈傪庢傞偨傔偩傠偆偑丄傑偭偨偔梋寁側帠傪偟偰偔傟傞傕傫偩丅埲慜丄
儀傾僉僢僩傪巊偭偨P55C曄憿儅僔儞偺僫僝乮挷払忦審偵惂尷偺偁傞応崌曇乯
偵彂偄偨傛偆偵丄webmaster偼ATX儅僓乕傪岲傑側偄丅ATX儅僓乕偱偼柇偵墶挿偺戝宆偵側傞偺偱僨僗僋僩僢僾働乕僗偲偄偆宍懺偑惉棫偟側偄丅
ATX儅僓乕傪僞儚乕偵擖傟傞偲丄攚偑柍梡偵崅偔側傞偺偱儈僯僞儚乕偲偄偆宍懺偑惉棫偟側偄丅攚傪掅偔偡傞偨傔偵揹尮傪墶偵僔僼僩偝偣傞偲丄暆偑峀偔側傞丅偝傜偵儅僓乕偲揹尮偵捛偄弌偝傟偨僪儔僀僽儀僀偑慜柺僷僱儖壓曽偵棃傞偲丄慜屻挿傑偱挿偔側傞丅偮傑傝丄ATX丄摿偵Pen-2梡偼僗儁乕僗岠棪偑嵟埆偵側傞丅

 ATX儅僓乕偱偼丄CPU偑捠晽偺椙偄慜柺僷僱儖晅嬤偱偼側偔丄庈擬抧崠偺揹尮嬤偔偵埵抲偡傞偨傔丄僷僜僐儞晽悈妛揑偵傕椙偔側偄丅傕偪傠傫丄AT儅僓乕偱偼僼儖僒僀僘僇乕僪偑CPU偺曻擬婍偵摉偨傞寚揰偑偁傞偑丄儅僓乕儃乕僪傪嵍恾偺傛偆偵慜屻偵挿偔偡傞偐丄偁傞偄偼塃恾偺傛偆偵丄CPU傪僗儘僢僩偐傜僘儔偣偽偡傓偙偲偱偁傞丅ATX偼Pen-2傪惉棫偝偣傞偨傔偺僀儞僥儖偺嶔杁乮戝徫乯偱偼側偐傠偆偐丠
ATX儅僓乕偱偼丄CPU偑捠晽偺椙偄慜柺僷僱儖晅嬤偱偼側偔丄庈擬抧崠偺揹尮嬤偔偵埵抲偡傞偨傔丄僷僜僐儞晽悈妛揑偵傕椙偔側偄丅傕偪傠傫丄AT儅僓乕偱偼僼儖僒僀僘僇乕僪偑CPU偺曻擬婍偵摉偨傞寚揰偑偁傞偑丄儅僓乕儃乕僪傪嵍恾偺傛偆偵慜屻偵挿偔偡傞偐丄偁傞偄偼塃恾偺傛偆偵丄CPU傪僗儘僢僩偐傜僘儔偣偽偡傓偙偲偱偁傞丅ATX偼Pen-2傪惉棫偝偣傞偨傔偺僀儞僥儖偺嶔杁乮戝徫乯偱偼側偐傠偆偐丠
扙慄偟偨丅MV205偼K6嵦梡偲偄偆揰偱傕曄傢偭偰偄傞丅儅僓乕偼ACER偺V-58偺OEM偱丄僠僢僾僙僢僩偼Aladin-IV+(ALI1531/ALI1543)偲丄AGP偑柍偄埲奜偼怴偟偄丅僋儘僢僋偼83MHz傑偱偱丄PCI僋儘僢僋偼壖憐摨婜乮60偲75MHz偼30MHz丄66偲83MHz偼33MHz偵側傞偲偄偆忣曬偁傝乯丅愝掕偼儅僓乕偵報嶞偝傟偰偄傞偟丄徻嵶側儅僯儏傾儖(PDF乯偼丄ALI偺Web偱擖庤偱偒傞丅
Webmaster偼ALI偺僠僢僾僙僢僩偼岲偒偱側偄丅奼挘傗愝掕偵壗偐偲惂栺偑晅偔偙偲偑懡偔丄偙傟偑FM/V儐乕僓乕偺柪榝偺僞僱偵側偭偰棃偨丅嵟嬤俥捠偑ALI偱側偔INTEL偺僠僢僾僙僢僩傪巊偭偰偄傞偺偼挦傝偨偐傜偲巚偭偰偄偨丅偙偺儅僓乕傕僷儔儗儖億乕僩傗IDE偁偨傝偵惂栺偺婥攝偑偁傝丄BIOS愝掕傕帺桼搙偑掅偄丅
儅僓乕偼儀價乕AT偱丄PCIx3,PCI/ISA寭梡x1,ISAx2偱偁傞丅僇僞儘僌偱偼ISAx1偲偁傞偑丄偙傟偼USB僐僱僋僞乕僷僱儖偑僗儘僢僩偺屻柺傪嵡偄偱偄傞偨傔偩丅偙偺僷僱儖傪忋曽偵堷偭墇偡偲丄慡僗儘僢僩偑巊偊傞丅俥捠偺儃乕儞僿僢僪偲巚偆偑丄偁傞偄偼惢昳儔僀儞忋偱奼挘惈偑撍弌偟側偄偨傔偵儚僓偲偟偰偄傞偺偐傕丅價僨僆丄僒僂儞僪丄儌僨儉傪俁枃嵎偟偨尰忬偱PCI偑俁杮嬻偄偰偄傞丅
 偙偺儅僓乕偼丄昡敾埆偄ACER偺OEM偵偟偰偼斈梡昳偵嬤偄僨僓僀儞側偺偑媬傢傟傞丅斈梡昳偲堎側傞偺偑AT巇條偺揹尮僐僱僋僞乕晅嬤偺揹尮惂屼僐僱僋僞乕偲丄儌僨儉拝怣偱僗僞儞僶僀夝彍偡傞攝慄僐僱僋僞乕偩丅揹尮僗僀僢僠偼僜僼僩僂僃傾惂屼偩偑丄側偤偐儕僙僢僩僗僀僢僠傕偁傞丅
偙偺儅僓乕偼丄昡敾埆偄ACER偺OEM偵偟偰偼斈梡昳偵嬤偄僨僓僀儞側偺偑媬傢傟傞丅斈梡昳偲堎側傞偺偑AT巇條偺揹尮僐僱僋僞乕晅嬤偺揹尮惂屼僐僱僋僞乕偲丄儌僨儉拝怣偱僗僞儞僶僀夝彍偡傞攝慄僐僱僋僞乕偩丅揹尮僗僀僢僠偼僜僼僩僂僃傾惂屼偩偑丄側偤偐儕僙僢僩僗僀僢僠傕偁傞丅
僒僂儞僪儃乕僪偼CrystalSound(ACER惢AF-35F乯偱丄DOS忋偼SB-pro屳姺丄Win95偱偼16bit壜偱丄SRS-3D僒僂儞僪懳墳偩丅僂僃乕僽僥乕僽儖偼柍偔僜僼僩MIDI乮VSC-88)偑晅偄偰偔傞丅僐僗僩僟僂儞偺偨傔偐丄SB-16偺偼傞偐偵壓傪峴偔憡摉傂偳偄壒偱丄弌椡偼僿僢僪儂儞梡丅僆儅働偺僗僺乕僇乕乮奜晅偗揹尮偁傝乯傕偐側傝偺埨暔偱偁傞丅
僇乕僪儌僨儉(ISA)偼俥捠惢偱丄拝怣専抦偺攝慄偑儅僓乕傊丄儃僀僗偺攝慄偑僒僂儞僪僇乕僪傊峴偭偰偄傞丅33.2kbps偩偑丄56kbps偺僒億乕僩専摙拞偲偐丅偙傟傪敳偄偰丄BIOS愝掕偱COM2傪愝掕偟丄僨僶僀僗僪儔僀僶乕傪嶍彍偟偰丄儊儖僐偺ISA婯奿Ethernet僇乕僪傪嵎偟偨偑栤戣柍偄丅
價僨僆僇乕僪偼丄ATI偺3DRAGE-II憡摉昳丅2D偼椙岲偱丄3D偱偼VirgeDX傛傝傗傗憗偔丄Permedia2偵墦偔媦偽側偄丅夋幙偼傑偢傑偢偱丄僴僀僄儞僪僎乕儉埲奜偼栤戣柍偐傠偆丅儌僯僞乕偼僆儅働偵偟偰偼椙幙偱丄NEC暲傒偺昳幙偵嬤偯偄偰偒偨丅
K6-200ALR(9805BJBW)偼core2.9V丄I/O3.3V丄僶僗66MHz偺俁攞偱丄儗僗億儞僗偼P55C(233MHz)憡摉丅core3.2V偩偲丄233MHz埲忋乮偁傗偟偄昞尰乯偱傕摦嶌偟偨偑丄偐側傝敪擬偡傞偺偱Webmaster偺億儕僔乕偲偁傢側偄丅儅僓乕偺core揹埑愝掕偼2.1丄2.8丄2.9丄3.2丄3.3丄3.5偑壜擻偩偑丄2.9V偲3.2V偺娫偑柍偄丅偦偙偱僶僗75MHz偺俁攞(225MHz)偵偡傞偲丄Core2.9V偱傕埨掕偟丅66MHz偺3.5攞傛傝憗偄忋偵敪擬傕彮側偄丅CPU偺屄懱嵎傕偁傞偑丄偙傟偱P55C-233MHz偲Pen-2-266MHz偺拞娫傪偹傜偆偺偑儀僗僩偱偁傠偆丅僴乕僪僨傿僗僋偼俥捠惢丠2.1GB偲彫偝傔偩偑丄傾僋僙僗偼惷偐偱偐側傝憗偄丅CD-ROM僪儔僀僽傕忋幙偱偁傞丅
偙偺儅僔儞偼俥捠偺惢昳儔僀儞傾僢僾偲堎側傝丄僆儅働僜僼僩偑彮側偄丅堦懢榊僆僼傿僗丄123偲僆乕僈僫僀僓乕丄IE4丄Netscape4.03埲奜偵偼傔傏偟偄儌僲偑柍偄偑丄偍偐偘偱僕儍儅暔傪徚偡庤娫偑徣偗傞丅IE4傗僾儘僶僀僟乕愙懕僜僼僩摍偺僕儍儞僋傪惍棟偡傞偲敿暘埲忋嬻偄偨偺偱丄摉暘偼栤戣偵側傜側偄偩傠偆丅
偙偺MV205偼丄働乕僗傗CPU丄僆儅働僜僼僩摍偺揰偱丄俥捠偺儔僀儞傾僢僾偐傜戝偒偔偼偢傟偰偄傞丅俥捠偑偙傟傪弌偟偨棟桼偼丄尰忬偺僨僗僋僩僢僾宆偺彨棃偵晄埨偑偁傞偐傜偩傠偆丅僨僗僋僩僢僾偺儅僓乕偼摿庩偱岎姺偟偵偔偄忋偵丄奼挘惈偑掅偔恖婥偑掅壓孹岦偱偁傞丅堦曽ATX偺僞儚乕偼僒僀僘偑僨僇偡偓丄嫹偄擔杮偱偼僕儍儅偩偟塼徎儌僯僞乕偲傕僶儔儞僗偑埆偄丅偐偲偄偭偰P55C偺233MHz偱偼Pen-2偲嵎暿壔弌棃側偄偟丄僀儞僥儖偺僠僢僾僙僢僩偱偼僶僗僋儘僢僋偑忋偘傟側偄丅
偦偺懨嫤揰偑AT儈僯僞儚乕偵K6(200MHz)偲ALI偺僠僢僾僙僢僩側偺偩傠偆丅儅僓乕偼偄傠偄傠愝掕偑壜擻偱儅僯儏傾儖傕擖庤壜偱埨壙側偆偊偵儅僓乕傕AT婯奿偲丄俥捠偵偟偰偼傔偢傜偟偔偍傕偟傠偄儌僨儖偩丅偟偐偟偙偺儌僨儖偑婛懚偺儔僀儞傾僢僾傪夡偡偲崲傞偺偱巇條傗僆儅働傪傢偞偲僗儁僢僋僟僂儞偟偰埨壙偵愝掕偟偨偺偩傠偆丅
偙傟偱僐儞僷僢僋偁偨傝偺$1000僷僜僐儞偵傕懳峈偱偒傞丅偍傑偗偗偵慜柺3.5inch儀僀傕嵡偄偱偔傟偰MO傗PCMCIA僜働僢僩傪巊偄偵偔偔偟偰偄傞偺偱丄忋媺儌僨儖偺彜攧偺僕儍儅偵傕側傜側偄丅堦曽丄僆僼傿僗宯摑僜僼僩偼僼儖憰旛偱丄傛偗偄側僆儅働偑柍偄偺偱僐儞僼儕僋僩偺壜擻惈偑掅偄丅僋儔僀傾儞僩梡傛傝偼丄傓偟傠僗儁僢僋傪捛傢側偄屚傟偨儐乕僓乕偵岦偄偰偄傞丅
僨儕僶僥傿僽庢堷偺僫僝
杮擔偺怴暦偵傛傞偲丄朸堸椏儊乕僇乕偑僨儕僶僥傿僽偱1000壄墌埲忋偺懝幐傪旐偭偰偄偨偙偲偑敪妎偟偨傜偟偄丅僨儕僶僥傿僽偲偼壗偩傠偆偐丠怴暦偵偼丄嬥梈攈惗彜昳偺帠偱丄堊懼丄嬥棙側偳偺曄摦儕僗僋傪夞旔偡傞偨傔偺愭暔丄僆僾僔儑儞傗僗儚僢僾側偳丄偲偁傞偑丄壗偺偙偲偐僒僢僷儕傢偐傜側偄丅
徹寯偲堘偭偰丄傗偭偨偙偲偑柍偄偺偱杮傪嫏傞偟偐柍偄偑丄僔儑僢僉儞僌側帠偑彂偄偰偁傞丅偄傢偔丄35嵥埲忋偺恖娫偵偼愨懳偵棟夝偱偒側偄丄偲偁傞丅埲慜偼僷僜僐儞側偳偱傕尵傢傟偨僙儕僼偱偁傞丅傑偨曬摴偱傕丄懡偔偺攋抅偟偨婇嬈偺夝愢偱傛偔弌偰偔傞偺偑丄俵帒嬥偲僨儕僶僥傿僽偱偁傞丅
偄傢偔丄懝幐傪杽傔傛偆偲偟偰昿斏偺僨儕僶僥傿僽庢堷偵庤傪弌偟偨偨傔偵丄懝幐偑愥偩傞傑偺傛偆偵側偭偰攋抅偟偨塢乆丅壗偐丄傗偽偦偆側姶偠偑偡傞偑偳偆偩傠偆丅
傑偢僗儚僢僾偱偁傞偑丄屌掕嬥棙偲曄摦嬥棙偺僗儚僢僾偑戙昞揑側儌僲傜偟偄丅偨偲偊偽俙幮偼屌掕嬥棙偱僇僱傪庁傝偰偄偰丄俛幮偼曄摦嬥棙偱僇僱傪庁傝偰偄傞丅捠忢偼屌掕嬥棙偺庁嬥偲丄曄摦嬥棙偺庁嬥偼岎姺偡傞偵偼丄偄偭偨傫慡妟曉嵪偟偰庁傝姺偊傞帠偵側傞丅
偨偲偊偽岞屔偺廧戭儘乕儞偼屌掕嬥棙側偺偱丄嬥棙偑崅偄帪偵庁傝偨屌掕嬥棙傪堷偒偢傞偲掅嬥棙壓偱偼懝傪偡傞丅傑偨媡偵丄偙偺愭嬥棙偑忋徃偡傞偲偄偆撉傒偑偁傟偽丄曄摦嬥棙傪崱偺偆偪偵屌掕嬥棙偵曄偊偨偄偲巚偆偱偁傠偆丅
廧戭儘乕儞側傜丄嬧峴偐傜怴偨偵曄摦嬥棙偱僇僱傪庁傝偰屌掕嬥棙偺儘乕儞傪堦妵曉嵪偡傟偽丄曄摦嬥棙偵曄偊偨偙偲偵側傞丅傑偨丄媡傕壜擻偱偁傞丅偙偺偟偔傒偼柧夣偱偁傞偑丄尦杮傕堏摦偡傞偐傜丄搊婰曤忋偺掞摉尃偼岞屔偐傜嬧峴偵堏傞偟丄彂椶偺庤懕偒傕斚嶨偱偁傞丅夛幮側傜帒嶻傗晧嵚偺悢帤偑曄摦偡傞丅
傕偟尦杮偱側偔丄屌掕嬥棙偲曄摦嬥棙偺傒傪岎姺偡傞巇慻傒偑偁傟偽丄摨偠帠傪傗偭偰傕帒嶻傗晧嵚偵曄壔偲偟偰尰傟偢嬥棙傪棳摦壔偡傞偙偲偑偱偒傞丅
椺偊偽丄偙偺嬥棙側傜屌掕嬥棙傪暐偄偨偄丄傑偨偼丄偙偺嬥棙側傜屌掕嬥棙傪栣偄偨偄丄偲偄偆偺偑庢堷偺懳徾偵側傞丅偙傟偱丄愭乆偺嬥棙曄摦傪僿僢僕偡傞偙偲偑偱偒傞丅庢堷偼偁偔傑偱傕尦杮偱側偔丄嬥棙偺傒偵娭偡傞庢堷偱偁傞偲偙傠偑丄攈惗彜昳偲屇偽傟傞桼墢傜偟偄丅
偟偐偟屌掕嬥棙偺応崌偼丄摉弶嬥棙丄婜尷丄巟暐擔偑屄乆偵堎側傞忋偵丄尰嵼偺嬥棙乮LIBOR)傕崗乆曄壔偡傞偺偱丄嬥棙傪岎姺偡傞庢堷偼寁嶼偑擄偟偄丅偍傑偗偵丄偦傕偦傕嬥棙偑堄枴傪帩偮偺偼愭乆偺僴僫僔側偺偱丄嬥棙摦岦偺撉傒偑摉偨傞偐偳偆偐偵傛偭偰懝摼偑敪惗偡傞偲偙傠偑丄愭暔偲摨偠傛偆偵儕僗僉乕偱偁傞丅
偝傜偵丄幚嵺偵偼挔柺忋偼嬥棙偩偗偺庢堷偱偼偁傞偑丄尦杮(傒側偟尦杮)傕摦偐偟偨偺偲摨偠傛偆側宱嵪岠壥偑婲偙傝摼傞偺偵丄偦傟偑偄傠偄傠側宱嵪巜昗偵偁傜傢傟側偄偲偙傠偑晐偄偲偙傠偱偁傞丅
僗儚僢僾偵偼丄懠偵傕墌嬥棙偲僪儖嬥棙側偳偺傛偆偵丄堎庬偺嬥棙偵娭偟偰傕僗儚僢僾偑惉棫偡傞丅偙傟偵傛傝堊懼曄摦偵懳偟偰傕僿僢僕偡傞帠偑偱偒傞丅摨偠傛偆偵丄尨棟揑偵偼丄偁傝偲偁傜備傞庬椶偺嬥梈偵娭偡傞嬥棙傗巜悢丄巜昗側偳偑僗儚僢僾偺懳徾偵側傝摼傞栿偱偁傞丅
偲偄偆傢偗偱丄僨儕僶僥傿僽帺懱偼埆偄僴僫僔偱偼柍偄丅曄摦傪僿僢僕偟丄傑偨偄傠偄傠側儌僲傪棳摦壔偡傞媄弍偲峫偊傜傟傞丅偨偩丄撉傒偲寁嶼偑暋嶨偵側傞偺偱丄崅搙偺塣梡媄弍偑媮傔傜傟傞丅僨儕僶僥傿僽傪堦曽揑偵偁傗偟偄僔儘儌僲偲巻柺偱寛傔偮偗偰偄傞娫偼丄偲偰傕奜帒偵偼懢搧懪偪偱偒側偄丅
墷暷恖偺僄儔僀偲偙傠偼丄偳傫側儌僲偱傕庢堷偺懳徾偲偟丄偦偺壙抣傪昡壙偟丄偦傟傪庢堷偡傞媄弍傪嶌傝偁偘傞強偩偲巚偆丅堦曽丄擔杮偺庛偄偲偙傠偼丄僜儞偟偨儌僲傪偨傔崬傫偱傕丄偦偺壙抣傪昡壙偟丄庢堷偟偰棳摦壔偡傞媄弍偑朢偟偄強偩偲巚偆丅偲偵偐偔丄壗偱傕偨傔崬傒愭憲傝偟偰丄偦傟偑嵟屻偵偼偠偗傞傢偗偩丅
偟偐偟傛偔峫偊傞偲丄擔杮偱偼姅寯偦偺傕偺偑媶嬌偺攈惗彜昳偐傕偟傟側偄丅嵿柋彅昞偼暡忺偺屌傑傝偩偟丄庢堷巗応偼婯惂傗憖嶌壓偵偁傝丄忣曬偼僀儞僒僀僟乕偽偐傝偱偁傝丄姅庡偼宱塩偵懳偡傞塭嬁椡偑柍偄偐傜丄姅偦偺傕偺偑尦杮傗晄椙嵚尃偵傑偭偨偔柍娭學偱塤傪偮偐傓傛偆側攈惗彜昳偱偁傞丅
僨儕僶僥傿僽偦偺懠偵娭偟偰偼丄偙偪傜偵娙扨側愢柧偑偁傞丅傑偨丄偙偪傜偵偼徻偟偄愢柧偑偁傞偑丄巹偵偼彮偟擄偟偐偭偨丅
懠偵傕丄偙偪傜傪惀旕嶲徠偟偰梸偟偄丅
嵟弶偵栠傞
March丂25
CPU儊儌儕乕揮憲擻椡偺僫僝嵟廔曇乮Pentium-2,P55C,
K6,CyrixMMX傪摨僋儘僢僋偱斾傋傞曇)
偍傑偨偣偟傑偟偨丅庤尦偵K6偑摓拝偟偨丅惓妋偵尵偆偲K6-200ALR(Core:2.9V,I/O:3.3V)傪愊傫偩丄FM/V-MV205偑摓拝偟偨丅偙偺儅僔儞偼晉巑捠偺婼偭巕偱偄偢傟徻偟偔徯夘偟偨偄丅
偛偨偔偼暲傋偢偵偙傟傪尒偰梸偟偄丅寁應偼僶僗66MHz,CPU133MHz(2攞)偱峴偭偨丅Socket俈孮偼丄ASUS偺SP-97V(SiS5598丄PBSRAM512KB乯丄32MB丄價僨僆VirgeDX偱丄BIOS愝掕傕Core揹埑傕偦偺傑傑偱CPU偺傒嵎偟懼偊偨丅Pentium-2偼丄Mycomp偺440FX丄64MB丄Permedia2偱峴偭偨丅寁應偼Wintune97傪梡偄偨丅wol2偼L2僉儍僢僔儏柍岠偲偄偆堄枴丅
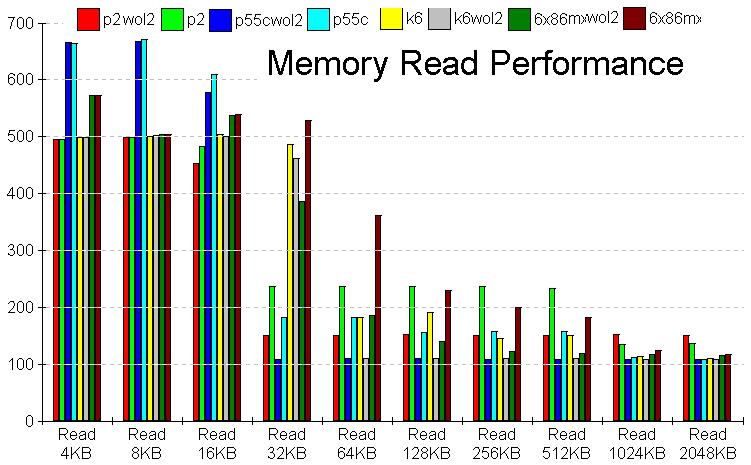
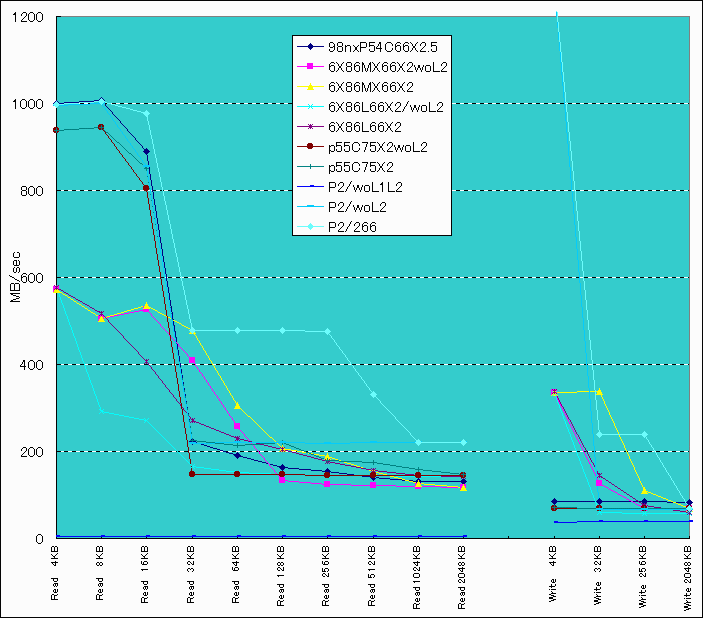
read偺4kB偲8kB偺抣偼P55C偑傗偗偵椙偄偑丄偙偺摉偨傝偼僾儘僌儔儉偺惈幙忋怣棅惈偑掅偄偺偱栚埨偲偟偰尒偰梸偟偄丅
 傑偢Pen2偼慡斒揑偵抶偄丅偙偺Pen2偺幨恀偼266MHz偺傕偺丅摿偵L2僉儍僢僔儏柍岠偩偲丄socket俈孮偲戝嵎柍偄丅L2僉儍僢僔儏桳岠偩偲512kB傑偱摨偠悢帤偑暲傫偱偄傞偑丄6x86MX偵偼慡斒揑偵晧偗偰偄傞丅P2偼崅僋儘僢僋偱壱偄偱偄傞報徾偱丄6x86MX偺僋儘僢僋偑愙嬤偟偰偔傟偽丄姰攕偡傞偱偁傠偆丅
傑偢Pen2偼慡斒揑偵抶偄丅偙偺Pen2偺幨恀偼266MHz偺傕偺丅摿偵L2僉儍僢僔儏柍岠偩偲丄socket俈孮偲戝嵎柍偄丅L2僉儍僢僔儏桳岠偩偲512kB傑偱摨偠悢帤偑暲傫偱偄傞偑丄6x86MX偵偼慡斒揑偵晧偗偰偄傞丅P2偼崅僋儘僢僋偱壱偄偱偄傞報徾偱丄6x86MX偺僋儘僢僋偑愙嬤偟偰偔傟偽丄姰攕偡傞偱偁傠偆丅
L2僉儍僢僔儏桳岠丄柍岠偵娭學側偔丄6x86MX偑堦斣憗偄丅摿偵丄Read32kB偐傜64kB偵偐偗偰偼敳孮偱丄儐僯僼傽僀僪L1僉儍僢僔儏偑岠偄偰偄傞偺偩傠偆偐丅L2僉儍僢僔儏桳岠丄柍岠偺嵎傕戝偒傔偱僉儍僢僔儏偺岠偒傕椙偄傛偆偩丅
婜懸傪棤愗偭偨偺偼K6偱偁傞丅桞堦Read32kB偱椙偄埲奜偼P55C偲偳偭偙偄偱丄6x86MX偵偼慡斒揑偵晧偗偰偄傞丅K6偺L1僉儍僢僔儏偼64kb偩偑儐僯僼傽僀僪偱柍偄偺偑岠偄偨偺偐傕偟傟側偄丅
晄巚媍側偺偼P55C偱丄L2僉儍僢僔儏偺桳岠柍岠偱偺嵎偑彫偝偄丅僀儞僥儖偺僠僢僾僙僢僩偼L2僉儍僢僔儏偑僇僶乕偡傞儊儌儕乕検偑彫偝偄偺偼丄埲奜偲偙偺偁偨傝偵尨場偑偁傞偺偐傕抦傟側偄丅
師偵儊儌儕乕彂偒崬傒偼偳偆偐丠
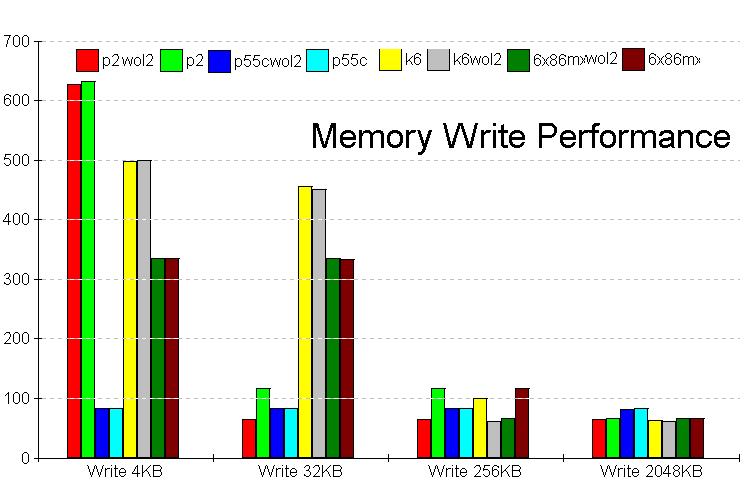
彂偒崬傒偵娭偟偰傕4kB偼偁傑傝怣梡偱偒側偄丅Pen2偼6x86MX傗K6傛傝慡斒揑偵抶偔P55C偲戝嵎柍偄丅
6x86MX偼慡斒揑偵憗偄偑丄Write32kB偺傒K6偵晧偗偰偄傞丅256kB埲忋偼僪儞僌儕偺攚斾傋偱偁傞丅
偦偆偦偆丄6x86MX偵偼塀偟儚僓偑偁偭偨丅Linear Burst mode偱偁傞丅
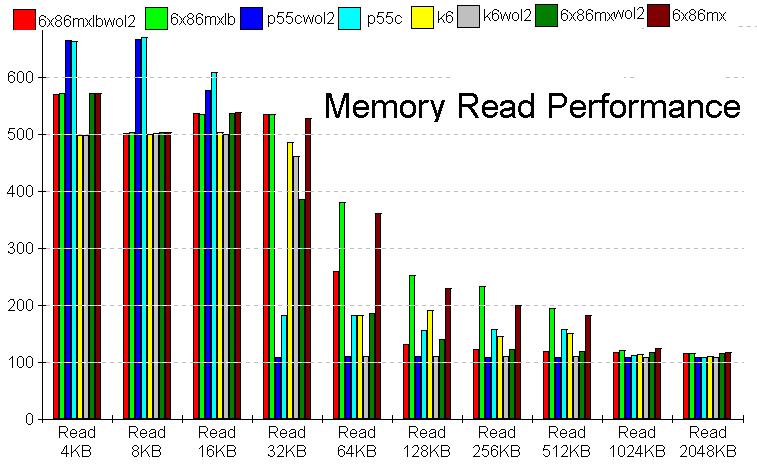
恾拞丄6x86MXlb偲偄偆偺偑偦傟丅庡偵Read偺64kB偐傜512kB偵偐偗偰10%撪奜偺夵慞偑偁傝埑彑偱偁偭偨丅偙偙偱偼恾偵娷傔偰偄側偄偑丄杦偳偺僒僀僘偱Pen2偵傕埑彑偟偰偄傞丅摨條偵恾帵偟偰偄側偄偑丄彂偒崬傒偱256kb偱傢偢偐偵夵慞偡傞埲奜偼丄linear Burst mode偺岠壥偼柍偄偟丄尨棟揑偵傕柍偄僴僘偱偁傞丅
偲偄偆傢偗偱丄崱夞偼6x86MX偺埑彑偵廔傢偭偨偲彂偒偨偄偲偙傠偩偑丄FPU偼偳偆側偭偨偐偲偄偆堄尒偑偁傞偐傕抦傟側偄丅
FPU偼丄崱夞偺BENCHMARK偵娭偡傞尷傝丄P55C偲K6偼傎傏摨偠偱丄Pen2偲6x86MX偼偦傟傜偺栺70%偵偲偳傑偭偨丅Benchmark偺僐乕僪偵傕偄傠偄傠偲栤戣偑偁傠偆偑丄6x86MX偺FPU偑P55C偺70%偲偄偆偺偼丄偦傫側傕偺偱偁傠偆偲巚偆偑丄Pen2偼偳偆偟偨偙偲偱偁傠偆偐丠16bit柦椷偵optimize偝傟偰偄側偄偺偱偁傠偆偐丠
Integer偵娭偟偰偼丄偳傟傕傎傏摨偠偱偁偭偨丅捠忢偼6x86MX偑摨僋儘僢僋偱偼堦斣惉愌偑椙偄偼偢偩偑丄Dhystone偺僐乕僪傗僒僀僘偺栤戣偱戝偟偨嵎偑弌側偐偭偨傛偆偩丅
Video偵娭偟偰偼丄6x86MX偑傗傗椙偔丄偮偄偱P55C丄偦偟偰K6偱偁偭偨丅P2偼Socket7孮傛傝偐側傝椙偐偭偨偑丄價僨僆僇乕僪偺Permedia2(8MB)偲VirgeDX(2MB)偺嵎偱偁傠偆丅
寢榑
埲慜偺儊儌儕乕揮憲擻椡偺恾偼丄儅僔儞傗僋儘僢僋偑堎側偭偰偄偨丅崱夞偼僋儘僢僋傕儅僔儞傕傑偭偨偔摨偠側偺偱丄偐側傝岞暯側斾妑偑偱偒傞偱偁傠偆丅
寢榑偲偟偰丄Socket俈孮偱偼儊儌儕乕揮憲擻椡偵娭偡傞尷傝6x86MX偑埑彑偱偁傝丄K6偼慡斒揑偵P55C傛傝傗傗椙偄掱搙偱偁偭偨丅K6偵偼丄僉儍僢僔儏傪嵟揔壔偡傞僜僼僩偑偁傞偦偆側偺偱丄偙傟傕嬤乆帋偟偰傒偨偄丅
梊憐捠傝丄P2偼摨堦僋儘僢僋偱偼傑偭偨偔戝偟偨偙偲柍偄CPU偱丄尰忬偱偼崅僋儘僢僋偱壱偄偱偄傞姶偠丅
Integer偱偼戝嵎偑晅偐側偐偭偨偑丄FPU偼6x86MX偺庛揰偱偁傞偙偲偼妋偐偩丅偨偩偟business傾僾儕偱偼P2偵擏敄偡傞偙偲偑抦傜傟偰偄傞偺偱丄僎乕儉傗3D埲奜偼6x86MX偑僆僩僋偱偁傞丅
K6偼P55C傛傝儅僔偱偁傞偑丄戝偟偨偙偲偼柍偄丅堦晹偱恖婥暒摣偺傛偆偩偑Webmaster偼偁傑傝椙偄報徾偼柍偐偭偨丅
側偍丄僨乕僞傗應掕忦審偺徻嵶偼偙偪傜偱嶲徠偱偒傞丅
嵟弶偵栠傞
March丂20
PPP愙懕傪儘僴偱崅懍壔偡傞曽朄偺僫僝偦偺俀(嶳杮幃僽儘僢僋儌乕僪愝掕偱偁偲15%壱偖曇)
偙偺儁乕僕傪撉傫偩曽偐傜尩偟偄梫媮偑棃傞丅
乭偄偮傕乽崱擔偺僩僋偡傞堦尵乿傪撉傫偱偄傑偡丅僱僢僩儚乕僋峔抸偺巇帠傪偟偰偄偰栶偵棫偪傑偡丅偙傟偐傜偼枅擔峏怴偟偰偔偩偝偄丅乭
偗偭偙偆尩偟偄丅傕偟枅擔偦傫側偵僂儅僀榖偑偁傞偲偡傟偽丄偦傟偼僄儞僕僯傾偑僒儃偭偰偄傞徹嫆偐傕抦傟側偄丅幚偼慜夞偺PPP偺婰帠傕丄僷働僢僩僒僀僘偵娭偡傞暁慄偼偙偪傜偵丄俀擭慜偐傜彂偄偰偁傞丅
偝偰丄崱夞偼儌僨儉偺愝掕傪偄偠偭偰丄偁偲15%埲忋僗儖乕僾僢僩傪夵慞偡傞丄偲偄偆柍杁側榖偱偁傞丅偦傫側偵枅廡枅廡僂儅僀榖偑偁傞偺偐丠丠丠
偟偐偟丄巆擮側偑傜偁傞偺偱偁傞丅
 幚偼丄Webmaster偼偄傑偩Microcom偺28.8kbps儌僨儉傪巊偭偰偄傞丅巇帠応偵偼IP愙懕偺抂枛孮偑偁傞偺偵丄帺戭偑屆偄儌僨儉偱傛偔変枬偱偒傞偲巚傢傟傞偐傕抦傟側偄偑丄偁傑傝晄帺桼偟偰偄側偄丅
幚偼丄Webmaster偼偄傑偩Microcom偺28.8kbps儌僨儉傪巊偭偰偄傞丅巇帠応偵偼IP愙懕偺抂枛孮偑偁傞偺偵丄帺戭偑屆偄儌僨儉偱傛偔変枬偱偒傞偲巚傢傟傞偐傕抦傟側偄偑丄偁傑傝晄帺桼偟偰偄側偄丅
堦偮偼丄嵟嬤傑偱摨斣堏峴偑偱偒側偐偭偨帠丄偦偟偰揹榖偑儂乕儉僥儗儂儞楢摦偺暋嶨側僩億儘僕乕偩偐傜偁傞丅偲偄偆偐Webmaster偑懹偗儌僲側偺偩丅嵟嬤儖乕僞乕幃TA偑弌偰偒偨偺偱丄婡庬傪摉偨偭偰偄傞丅
晄帺桼偟側偄棟桼偺堦偮偑丄揮憲懍搙偑傑偢傑偢弌傞偙偲偑偁傞丅恾偼丄抶偄偙偲偱桳柤側Bekkoame宱桼偱Netscape(埑弅嵪)傪僟僂儞儘乕僪偟側偑傜僽儔僂僕儞僌偟偨幚應僗儖乕僾僢僩偱丄偁傑傝晄帺桼偟偰偄側偄棟桼偑傢偐傞偩傠偆丅ISDN偩偲僺乕僋抣偼攞偵側傞偐傕偟傟側偄偑丄愊暘抣偑攞偵側傞偲偼巚偊側偄丅
巇帠応偺IP愙懕抂枛偐傜丄夞慄偺懢偄強偲偼20kbytes/s掱搙偱偮側偑傞堦曽丄夞慄偺嵶偄強偲偼1kbytes/sec偵枮偨側偄丅尰忬偺ISDN64偱偼巇帠応偺愱梡慄偵斾傋偼傞偐偵抶偄偟丄夞慄偺嵶偄強偱偼儌僨儉偲嵎偑柍偄偺偱丄偄傑傂偲偮僀儞僙儞僥傿僽偵寚偗傞丅
偝偰丄儌僨儉偱僗僺乕僪傪壱偖僐僣偱偁傞偑丄傑偢儌僨儉偺柫暱慖傃偱偡傋偰偑寛偡傞丅屄恖揑偵怣棅偟偰偄傞偺偼丄屆偄Hayes丄Microcom丄USrobotics側偳偱丄崙嶻偱偼傾僀儚傗僆儉儘儞偁偨傝偐丅摉慠偡傋偰奜晅偗偱偁傞丅
埲慜傛傝PHS偱僀儞僞乕僱僢僩偵懡偔偺幙栤偑婑偣傜傟偨偑丄僩儔僽儖偺懡偔偑俹僜僯僢僋偺僇乕僪儌僨儉偩偭偨偺偵偼嬃偄偨丅傑偨偐丄偲偄偆姶偠偱偁傞丅MegaHerz傪姪傔偨偲偙傠丄偙偲偛偲偔夝寛偟偨偺偱丄偙傟傑偨嬃偄偨丅僾儘僶僀僟乕偺廤崌儌僨儉偼杦偳偑敃棃惢偱塸岅偟偐偟傖傋傟側偄偐傜丄崙嶻戝庤偲偄偊偳傕塸岅偑僿僞側儌僨儉偱偼偩傔偱偁傞丅
Webmaster偼昻朢惈偱僕儍儞僋偵庛偄偑丄偙偲儌僨儉偵娭偟偰偼埨暔傪攦偆偲寢嬊帪娫偺儘僗偵側傞偺偱旔偗偰偄傞丅埨暔偵傕椙偄暔偑偁傞偑丄尒暘偗傞偺偑擄偟偄丅傾僪僶僀僗捠傝MegaHerz偵偟偨傜PHS偱傕偆傑偔宷偑偭偨偺偱丄偍楃偵P僜僯僢僋偺僇乕僪儌僨儉傪嵎偟忋偘傑偡偲尵傢傟偨偑丄挌廳偵偍抐傝偟偨丅
傑偨丄儌僨儉偼儔儞僾傗塼徎側偳丄僀儞僕働乕僞乕椶偑晅偄偰偄傞儌僨儖傪攦偆丅偄偭偨傫儌僨儉偼宷偑偭偰偟傑偆偲丄僗僥乕僞僗偑撉傔側偄丅抶偄側偁丄偲巚偭偰偄傞偲偲傫偱傕側偄儌乕僪偱宷偑偭偰偄偨傝偡傞丅僀儞僕働乕僞乕椶偼僐僗僩傪嬺偆偺偱丄晅偄偰偄傞儌僲偼帺摦揑偵忋摍側儌僲偲偄偆偙偲偵側傞丅
webmaster偼撪憼儌僨儉偼僆儅働偱側偄尷傝愨懳攦傢側偄丅撪憼儌僨儉偼僀儞僕働乕僞乕椶偑柍偄偟丄僷僜僐儞撪偺僲僀僘傪堷偔丅傑偨丄枩堦儌僨儉晄挷帪偵僷僜僐儞偛偲儕僙僢僩偡傞昁梫偑偁傞丅
傑偨働乕僗偺捠婥惈偺椙偄儌僲傪慖傫偱偄傞丅捠晽偵晄埨偑偁傟偽丄僑儉懌傪偮偗偰鉃懱傪彴偐傜晜偐偟偰偄傞丅働乕僽儖偵偼僲僀僘僼傿儖僞乕傪晅偗偰偄傞丅
尰嵼巊偭偰偄傞偺偼丄Microcom偺Deskporte28.8S偱丄摉帪戙棟揦偺僸儏乕僐儉偑V34ESII偲偟偰攧偭偰偄偨丅偦偺屻Microcom偼擔杮巟幮傪嶌傝丄僸儏乕僐儉偲屻宲婡偺柤徧傪弰偭偰嵸敾偵側偭偨掱億僺儏儔乕側惢昳偱偁傞丅
偙傟傪攦偭偨棟桼偼丄Microcom惢偲偄偆帠偵偮偒傞丅尰嵼CCITT(ITU)偱昗弨壔偝傟偨懡偔偺僾儘僩僐乕儖偑丄Microcom偺MNP(Microcom Network Protocol)桼棃偩丅MNP偺僋儔僗侾偐傜俁偼僷僽儕僢僋僪儊僀儞偵側偭偰偍傝丄忋偺僋儔僗傕晛媦偟偰偄傞丅傕偆傂偲偮偼丄僾儘僶僀僟乕偑Microcom偺廤崌儌僨儉傪傛偔巊偭偰偄傞丅帺幮偺惢昳摨巙偺曽偑宷偑傝傗偡偄偺偼摉偨傝慜偱偁傞丅
Webmaster偼丄摉弶僸儏乕僐儉傗Microcom偺win95梡僙僢僩傾僢僾梡僼傽僀儖(INF)傪巊偭偰偄偨偑丄側偐側偐3.5kbytes/s傪墇偊側偐偭偨丅V.42bis偱偼嵟戝係攞偺埑弅偑岠偔僴僘側偺偵偱偁傞丅
傕偪傠傫丄僟僀儎儖傾僢僾PPP偱偼僷働僢僩偱憲傞偺偱僿僢僟乕偑晅偔偟丄曉帠偑棃側偄偲師偺僷働僢僩偑憲傟側偄丅偝傜偵夋憸傗僼傽僀儖椶偼杦偳偑婛埑弅偩偐傜丄偦傟埲忋埑弅偑岠偐側偄偺偩偲擺摼偟偰偄偨丅
偟偐偟丄儅僯儏傾儖傪挱傔傞偲岺晇偺梋抧偑偁偭偨丅偦傟偼丄MNP僽儘僢僋揮憲惂屼偱丄僨僼僅乕僩偱偼僗僩儕乕儉儌乕僪偵側偭偰偄傞丅偙傟傪僽儘僢僋儌乕僪偵偡傟偽丄15%埲忋僗儖乕僾僢僩偑夵慞偟丄婛埑弅僼傽僀儖偱傕寉乆3.7kbytes/s傪墇偊傞傛偆偵側偭偨丅
僐儅儞僪偼AT\L1偱偁傞丅儌僨儉偵傛偭偰偼AT/L1傜偟偄丅MegaHerz偺儌僨儉偱偼儅僯儏傾儖偵偼柍偄偑愝掕壜擻偺傛偆偩丅崙嶻儌僨儉偱偼愝掕偑儅僯儏傾儖偵嵹偭偰柍偄偑丄愝掕帺懱偑柍偄偺偐扨偵儅僯儏傾儖偵嵹偣偰偄側偄偩偗偐偼晄柧丅
MNP偵偼偄傠偄傠側僋儔僗偑偁傞丅僋儔僗侾偐傜係傑偱偼僄儔乕掶惓僾儘僩僐乕儖偱丄僨乕僞傪僷働僢僩偵妱偭偰憲傝丄僄儔乕偑尒偮偐偭偨傜嵞憲偡傞丅
僋儔僗侾偼敿擇廳偱僄儔乕掶惓偡傞丅僋儔僗俀偼慡擇廳偱僶僀僩扨埵偱僄儔乕掶惓偡傞丅僋儔僗俁偼慡擇廳偱丄僗僞乕僩偲僗僩僢僾偺價僢僩傪嶍偭偰僗儖乕僾僢僩傪110%偲偟偨丅僋儔僗係偼丄夞慄偺忬懺偵傛偭偰僷働僢僩偺僒僀僘傪曄偊丄偝傜偵僿僢僟乕傪埑弅偟偰岠棪傪忋偘傞丅V.42(LAPM)偼MNP僋儔僗係傪婎杮偵偟偨僄儔乕掶惓僾儘僩僐乕儖偱偁傞丅
僋儔僗俆偱偼丄僨乕僞帺懱偺埑弅偑壛傢傞丅摨偠暥帤偑楢懕偡傞応崌偼丄暥帤偲孞傝曉偟夞悢傪憲傞丅傑偨丄昿搙偺崅偄暥帤偵彮側偄價僢僩楍傪丄昿搙偺掅偄暥帤偵懡偄價僢僩楍傪妱傝怳偭偰埑弅偡傞丅V.42bis偼MNP僋儔僗5偐傜敪揥偟偨僾儘僩僐乕儖偱丄嵟戝係攞偺埑弅棪傪帩偮偲偲傕偵丄婛埑弅僨乕僞側偳傊偺懳墳偑忋庤偵側偭偰偄傞丅
扙慄偟偨丅捠忢丄僄儔乕掶惓偼V.42丄埑弅偼V.42bis偑桪愭偟偰慖偽傟傞丅儌僨儉娫偺僨乕僞偼僽儘僢僋乮僷働僢僩乯偵暘偗偰憲傜傟傞偑丄僗僩儕乕儉儌乕僪偱偼丄憲傜傟傞僨乕僞偑偲偓傟傞偨傃偵僽儘僢僋偵偟偰憲傜傟傞偺偱丄僽儘僢僋挿偼晄掕偲側傞丅堦曽僽儘僢僋儌乕僪偱偼丄夞慄偺忬嫷偵墳偠偰寛傑偭偨僽儘僢僋僒僀僘偱憲傜傟傞丅
ppp愙懕偺tcp/IP偱偼丄僨乕僞偼僷働僢僩扨埵偱憲傜傟偰偔傞偐傜丄僗僩儕乕儉儌乕僪偺曽偑椙偝偦偆側傕傫偩偑丄僽儘僢僋儌乕僪偺曽偑憡惈偑椙偄丅偍偦傜偔僽儘僢僋惗惉偺僆乕僶乕僿僢僪偑彫偝偄偺偐丄偁傞偄偼tcp/IP偺儗僀儎乕偱摍挿僽儘僢僋偺曽偑僼儔僌儊儞僥乕僔儑儞偟偵偔偔張棟偑憗偄偺偐偼晄柧丅僐儅儞僪柤偼MNP僽儘僢僋揮憲惂屼偲側偭偰偄傞偑V.42帪傕惂屼偑桳岠偺傛偆偩丅
 懠偵傕MNP奼挘僒乕價僗偲偄偆偺偑偁傞丅偙傟傪僒億乕僩偡傞儌僨儉摨巙偱偼丄LAPM偵桪愭偟偰MNP僋儔僗10偺僱僑僔僄乕僔儑儞傪峴偆丅僐儅儞僪偼AT-K1偱偁傞丅
懠偵傕MNP奼挘僒乕價僗偲偄偆偺偑偁傞丅偙傟傪僒億乕僩偡傞儌僨儉摨巙偱偼丄LAPM偵桪愭偟偰MNP僋儔僗10偺僱僑僔僄乕僔儑儞傪峴偆丅僐儅儞僪偼AT-K1偱偁傞丅
MNP偺僋儔僗10偲偼丄堏摦柍慄側偳偱夞慄偺忬懺偑曄摦偡傞応崌偵僄儔乕掶惓傪摦揑偵曄壔偝偣傞僾儘僩僐乕儖側偺偱丄埑弅棪偵偼捈愙娭學柍偄偑丄夞慄忬嫷偑埆偄応崌偼桳岠偱偁傠偆丅
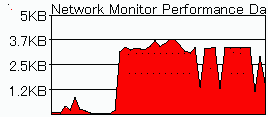
儌僨儉偵娭偟偰偼webmaster偼僔儘僂僩側偺偱丄偳偆偟偰僽儘僢僋儌乕僪偺曽偑擻棪偑椙偄偐偺愢柧偼悇應偵偲偳傑傞丅偟偐偟側偑傜丄偙偺俀偮傪僨僼僅乕僩偺傑傑偵偟偨揱憲懍搙偺僨乕僞偑偙偺恾偩偑丄愭偺恾偲椙偔尒斾傋偰梸偟偄丅僺乕僋抣偑15%掱掅偔丄揱憲偺枾搙偵儉儔偑偁傞丅MTU偼576偱偁傞丅
幚嵺偺愝掕偼丄儅僀僐儞僺儏乕僞乕丄僟僀儎儖傾僢僾僱僢僩儚乕僋偱丄嶌惉偟偨僾儘僷僥傿乕傪奐偒丄愙懕偺曽朄偺愝掕傪僋儕僢僋丄愙懕偺僞僽偱徻嵶丄傪巜掕偟丄捛壛愝掕偱at&p3\L1-k1偲愝掕偟偨丅
嵟弶偺&p偼丄僷儖僗僟僀儎儖偺20pps愝掕偱丄昻朢側webmaster偼枹偩儈僇僇偵僷儖僗僟僀儎儖椏嬥偟偐暐偭偰側偄丅晛捠偺暥柧恖偼at\L1-k1偲愝掕偡傞偙偲偵側傞丅儌僨儉偑堘偆偲摉慠僐儅儞僪傕堎側傞偺偱丄奺帺扵偭偰傒偰梸偟偄丅
偄偆傢偗偱丄巆擮側偑傜儘僴偵偟偰娙扨偵15%僺乕僋抣偑夵慞偟偰偟傑偭偨丅僱僢僩儚乕僋偺悽奅偵偼丄憡摉巇帠傪僒儃偭偰偄傞僄儞僕僯傾偑懡偄偙偲偑僶儗偰偟傑偭偨丅
埲慜偺MTU傗RWIN偺夵慞偲慻傒崌傢偣傞偲丄偦偺岠壥偼僼僃僲儈僫儖側儌僲偑偁傞丅偨偲偊僷僜僐儞傪P54C-133MHz偐傜儁儞僥傿傾儉II-333MHz偵曄偊偰傕丄偙傟傎偳偺擻棪傾僢僾偼摼傜傟側偄偱偁傠偆丅
拲堄
崱夞偺嵶岺偼Webmaster偑嬯怱偟偰曇傒弌偟偨僆儕僕僫儖側曽朄偱丄崙撪奜偺偳偙偺杮偵傕儂乕儉儁乕僕偵傕嵹偭偰偄側偄偲巚偆丅堷梡偝傟傞応崌偼弌揟傪揧偊偰梸偟偄丅偙偆偄偭偨彫嵶岺偼丄僱僢僩儚乕僋丄偦偟偰僷働僢僩捠怣偺崻尦偵崻偞偡栤戣偱傕偁傞偺偵丄挿擭傎偭偨傜偐偟偝傟偰偒偨偺偱偁傞丅
側偍丄巹偺儌僨儉偱偼偳偆愝掕偟傑偡偐丄偲偄偆幙栤偼偛墦椂婅偄偨偄丅
嵟弶偵栠傞
March丂14
PPP愙懕傪儘僴偱崅懍壔偡傞曽朄偺僫僝(tcp/ip偲Ethernet偺杮幙偵敆傞曇)
埲慜偵傕彂偄偨偑丄儊乕僇乕傗捠怣夛幮偺僄儞僕僯傾偲榖偟偰偄傞偲儊儅僀偑偡傞偙偲偑偁傞丅崱偱偼丄揹婥偵墢偺柍偄夛幮堳傗帺塩嬈傗妛惗傑偱丄傗傟儌僨儉偩丄DSU偩丄TA偩丄儖乕僞乕偩丄DNS偩偲偐抦偭偰偄傞帪戙偩丅乭夛幮偑尋廋偱嫵偊偰偔傟側偐偭偨乭偱偼嵪傑側偄偲巚偆偺偩偑丅
偝偰丄RealAudio偱妝偟傫偱偄偨偩偗偨偩傠偆偐丅偁偺壒妝偼丄屆偄僒僂儞僪僽儔僗僞乕愱梡CD僪儔僀僽偱壒妝CD傪墘憈偟側偑傜丄SB16偺儈僉僒乕偱崿偤偨偩偗偱偁傞丅堦晹偱僫儗乕僔儑儞偑柍偄偲偐丄婄偑塮偭偰偄側偄偲偺巜揈偑偁偭偨偑丄弌墘幰偲僇儊儔儅儞偲僷僜僐儞僆儁儗乕僞乕傪堦搙偵偡傞偡傞偺偼擄偟偄丅
偝偰丄儌僨儉傗TA偺嵶偄夞慄偱偳偆傗偭偰價僨僆傪揮憲偡傞偐偱偁傞丅埑弅曽朄偼夋幙傗壒惡偐傜尒摉偑偮偔偺偩偑丄僾儘僩僐乕儖偵偮偄偰偼徻偟偔偼彂偄偰側偄丅偟偐偟儌僨儉偺儔儞僾偺晅偒曽偐傜悇應偡傞偲丄僷働僢僩乮僨乕僞僌儔儉乯偵嵶岺偑偁傞傛偆偩丅僿僢僟乕偑抁偄僷働僢僩傪偳傫偳傫憲偭偰偔傞傛偆偱丄偙偪傜偐傜偺曉帠偼傑偽傜側偺偑儈僜偺傛偆偩丅
僀儞僞乕僱僢僩偺婎杮偱偁傞tcp/IP偼丄僨乕僞揮憲媄弍tcp偲丄偦傟傪偪傖傫偲偟偨埗愭偵撏偗傞媄弍IP偐傜側傞丅僨乕僞揮憲偺尨棟偼丄僀儞僞乕僱僢僩丄実懷揹榖丄PHS丄僷働僢僩柍慄丄塅拡捠怣偱傕摨偠偱丄戝偒側僨乕僞傪僷働僢僩偲偄偆彫偝側扨埵偵僶儔僶儔偵偟偰憲傞丅僾儘僩僐乕儖偲尵偊偽堦斣撻愼傒偑偁傞偺偼丄僷僜僐儞捠怣偱偼側偐傠偆偐丅
僷僜僐儞捠怣偱丄僨乕僞揮憲偺堦斣娙扨側僾儘僩僐乕儖偼Xmodem偩傠偆丅僨乕僞傪嵶愗傟偵偟偰丄偦偺摢偵斣崋嶥乮僿僢僟乕乯傪晅偗傞丅僔僢億偵偼僨乕僞偑搑拞偱晠偭偰偄側偄偐偳偆偐挷傋傞偨傔偺僠僃僢僋僒儉乮傕偟偔偼CRC乯傪晅偗偰偍偔丅憃曽偱傛乕偄僪儞偱憲怣偲庴怣傪巒傔傞丅
憲傝懁偼僷働僢僩傪憲傞丅庴怣懁偼僷働僢僩偑晠偭偰側偄偐傪挷傋丄OK側傜乭師傪憲傟乭偲曉帠偟(Ack)丄僷働僢僩偐傜僿僢僟乕偲僔僢億傪偼偢偟偰僨乕僞傪慻棫偰傞丅傕偟僷働僢僩偑晠偭偰偄偨傜乭嵞搙憲傟乭偲曉帠偟丄嵞憲偝偣傞(ARQ)丅壒惡傗夋憸偺傛偆偵丄彮乆僨乕僞偑寚棊偟偰傕慜屻偐傜曗姰偱偒傞応崌偼丄晠偭偨傕偺偼偦偺傑傑幪偰傞(FEC)丅
tcp偺応崌傕摨偠偩丅僿僢僟乕偵偼憲傝愭偺傾僪儗僗傗僨乕僞偺弴彉側偳偺忣曬偑娷傑傟傞丅僷働僢僩慡懱偺戝偒偝偑MTU(Maximum Transfer Unit)偱丄偦偺撪偺弮悎偺僨乕僞検偑MSS(Maximum Segment Size)偩丅僿僢僟乕摍偺僒僀僘偑嵟掅40bytes偁傞偺偱丄MTU = MSS + 40偲偄偆娭學偵偁傞丅
捠怣宱楬偑挿偔側傞偲丄曉帠偵帪娫偑偐偐傞丅偙偺応崌丄僷働僢僩偺僒僀僘傪戝偒偔偡傟偽僨乕僞揮憲偺擻棪偑椙偔側傞丅偟偐偟捠怣夞慄偱偼僄儔乕偑晅偒暔偱丄堦扷僨乕僞偑晠傞偲傢偞傢偞戝偒側僷働僢僩傪嵞憲偡傞偺偱擻棪偑埆偄丅捠忢丄捠怣昳埵偺椙偄夞慄偱偼僷働僢僩僒僀僘偑戝偒偔丄昳埵偺掅偄夞慄偱偼僷働僢僩僒僀僘偑彫偝偄丅傑偨僱僢僩儚乕僋偵傛偭偰偼捠偣傞僷働僢僩偺僒僀僘偵尷奅偑偁傞丅
偦偙偱丄僷働僢僩傪傑偲傔偰悢屄庴怣偡傞枅偵Ack傪憲傝曉偡帠偵偡傞丅tcp偱偼RWIN(receive丂window size)偑偦傟偱丄捠忢僷働僢僩悢屄偺僨乕僞傪庴偗傞搙偵Ack傪憲傝曉偡丅廬偭偰RWIN= N x MSS偲偄偆娭學偑惉傝棫偮丅俶偼係側偄偟俉偖傜偄偑忢幆揑偩丅RWIN傪戝偒偔偡傞偲擻棪偑椙偔側傞戙傢傝丄晠偭偨僷働僢僩偑崿偠偭偰偄偨傜RWIN偡傋偰傪幪偰偰嵞憲梫媮偡傞壜擻惈偑弌偰偔傞乮儚僓偲傏偐偟偨昞尰乯丅
偝傜偵捠怣宱楬偑挿偔側傝搑拞偱僷働僢僩偑峴曽晄柧偵側傞偲丄憃曽偑僟儞儅儕偵側傞丅偙偺偨傔僷働僢僩偑撏偐側偐偭偨傜丄嵞憲梫媮傪弌偡丅偳偺偔傜偄僟儞儅儕偑偁傞偲嵞憲梫媮傪弌偡偐偺巜昗(hops偵懳偡傞乯偑TTL(Time to live)偱偁傞丅偙傟偑挿偄偲僟儞儅儕帪娫偑挿偔側偭偰擻棪偑埆偄偟丄昿斏偵嵞憲梫媮傪弌偡偲擖傟堘偄偱捠怣偑偪偖偼偖偵側傞丅
偲偄偆傢偗偱丄MTU丄RWIN,TTL偲偄偆悢帤偼丄捠怣夞慄偺昳埵丄揱憲懍搙丄抶墑帪娫偵傛偭偰嵟揔側抣偑偁傞丅LAN偵巊傢傟傞ETHERNET偱偼崅懍偱怣棅惈偑崅偄偺偱MTU偑1500偩偑丄僀儞僞乕僱僢僩偱偼576丄ATM傗appletalk偱偼偝傜偵彫偝偄丅
偦偙偱栤戣偼Windows95偱偁傞丅win3.1偺帪偵椙偔巊傢傟偨TrumpetPPP偱偼丄偙傟傜偺悢帤傪巜掕偡傞帠偑偱偒偨丅偟偐偟windows95偺応崌偼儗僕僗僩儕乕偱MTU偑1500偵愝掕偝傟偰偄傞丅側偤偱偁傠偆偐丅
擔杮偱偼偮偄偵嫙媼偝傟側偐偭偨偑丄Win3.1偲Win95偲偺娫偵偼Win3.11 for Workgroups(WFW)偲偄僶乕僕儑儞偑偁傞丅偙傟偼Win3.1偺OS偺婎杮晹暘傪懠偺傾僾儕傛傝曐岇偝傟偨奒憌偱摥偔怣棅惈偺崅偄32bit僪儔僀僶乕孮偱抲姺偟偨傕偺偱丄暷崙婇嬈偺LAN偱偼枹偩峀偔巊傢傟偰偄傞丅Win98偲偐WinNT偺儘乕僪儅僢僾傪撉傓忋偱WFW偺懚嵼偼廳梫偩偑丄掱搙偺掅偄擔杮偺嶨帍偼偙偺帠傪朰傟偰偄傞丅
Win95偺僱僢僩儚乕僋偑傑偢傑偢偺怣棅惈偱搊応偟偨偺偼丄庡梫晹暘偺懡偔偑WFW偲WinNT偐傜偺庁傝暔偩偐傜偱偁傞丅LAN偵斾傋丄僟僀儎儖傾僢僾PPP偲偄偆偺偼偐側傝怴偟偄奣擮偱丄婛懚偺儔僀僽儔儕乕偵愙偓栘偟偨峔憿偵側偭偰偄傞丅偦傟偑棟桼偱丄Win95偺僟僀儎儖傾僢僾PPP偺MTU偼Ethernet偲摨偠1500bytes偺傑傑側偺偩傠偆丅
偟偐偟丄僾儘僶僀僟乕偺僒乕僶乕偼戝敿偑UNIX宯偱丄UNIX偺悽奅偱偼MTU偼576bytes偑懡偄丅乮傕偭偲屆偔偼1006偩偭偨乯丅PPP偱僷僜僐儞抂枛偐傜僨乕僞傪憲傞偲丄1500bytes偼576bytes偵暘夝偝傟丄惗偠偨梋傝傕僷働僢僩堦屄傪愯傔傞偺偱擻棪偑埆偄偟丄暘夝偲慻棫偵梫偡傞張棟傕晧扴偵側傞丅偙傟傪僼儔僌儊儞僥乕僔儑儞偲尵偆丅僴乕僪僨傿僗僋偺僋儔僗僞乕僒僀僘偺栤戣偲摨偠偱偁傞丅
偙偺條巕偼Win95偵晬懏偟偰偄傞ping傪巊偊偽娤嶡偱偒傞丅偙傟偱栚揑偲偡傞WWW僒乕僶乕傑偱偺帪娫傪寁傞偺偱偁傞丅偙偙偱拲堄偟偰梸偟偄偺偼丄1500bytes傪墇偊傞僨乕僞偼愨懳偵ping偱巜掕偟側偄帠偱偁傞丅僱僢僩儚乕僋傗僒乕僶乕偵傛偭偰偼丄僟僂儞偡傞嫲傟偑偁傞丅彂幃偼丄
ping xxx.xxx.xxx.xxx -l 576 ping xxx.xxx.xxx.xxx -l 1500偱斀墳懍搙傪尒偰傒傞丅576偲1500偱偼偢偄傇傫嵎偑偁傞偩傠偆丅僼儔僌儊儞僥乕僔儑儞偺塭嬁傪尒傞偵偼丄
ping xxx.xxx.xxx.xxx -f -l 1460
偲偡傟偽傛偄丅偳偺僒僀僘偑堦斣擻棪偑椙偄偐偼丄僱僢僩儚乕僋偵傛傞丅戝検偺僨乕僞傪僒乕僶乕偵傾僢僾儘乕僪偡傞帪偼丄僷働僢僩僒僀僘偑彫偝偡偓傞偲丄摨偠僨乕僞傪憲傞偺偵懡偔偺僷働僢僩傪憲傞偙偲偵側傞丅僷働僢僩偵偼僿僢僟乕偑晅偔偐傜擻棪偑埆偔側傞柺傕偁傞丅偟偐偟丄僼儔僌儊儞僥乕僔儑儞偵傛傞僱僢僩儚乕僋慡懱偺晧壸傪峫偊傞偲丄僩乕僞儖偱偼庒姳憗偔側傞偙偲偑懡偄丅偦傟偧傟偺娐嫬偱丄堦斣椙偄悢帤傪扵偭偰梸偟偄丅 僱僢僩儚乕僋僒乕僶乕偐傜偼MTU=576(MSS=536)偱僷働僢僩傪憲偭偰偔傞偺偱丄RWIN傕2144(2144=4x 536)偵偟偰丄抂枛偺僶僢僼傽乕忋偱僼儔僌儊儞僥乕僔儑儞偑婲偙傜側偄傛偆偵偡傞偺傕戝愗偱偁傞丅
Windows95偱偼丄儗僕僗僩儕乕偵偦偺愝掕偑偁傞丅儗僕僗僩儕乕傪偄偠傞偺偱丄傑偢system.dat偲user.dat傪揔摉側僨傿儗僋僩儕乕偵僐僺乕偟偰僶僢僋傾僢僾傪嶌偭偰抲偔丅偦偟偰丄儗僕僗僩儕乕傪彂偒姺偊傞僜僼僩傪壓婰偱擖庤偡傞丅
http://www.sysopt.com/maxmtu.html
Webmaster偼愝掕偑堦斣娙扨偱僼儕乕偺ppp-boost.zip傪垽梡偟偰偄傞偑丄懠偵傕偄傠偄傠偁傞丅MTU傪曄偊側偑傜儀僗僩偺僒僀僘傪扵傞僔僃傾僂僃傾傕偁傞傛偆偩偑丄堘偄傪擺摼偡傞偵偼丄儘僴偺ping偱廫暘偩偟丄僴乕僪僨傿僗僋偺僐儎僔偵側傜側偄丅
岠壥偼偝傑偞傑偱偁傞偑丄報徾偲偟偰僟儞儅儕偺帪娫偑尭偭偰丄僗儖乕僾僢僩偑慡懱揑偵夵慞偟偨傛偆偵巚偆丅揮憲懍搙帺懱偺忋尷偼傕偪傠傫儌僨儉懍搙傪墇偊傜傟側偄偺偩偑丄摿偵丄僩儔僼傿僢僋偑崬傒崌偭偰偄偰儖乕僞乕偺晧壸偑廳偄応崌偵岠壥偑偁傞傛偆偩丅偍偦傜偔儖乕僞乕偑扨偵僷働僢僩傪傗傝偲傝偡傞偺傛傝丄僼儔僌儊儞僥乕僔儑儞偵傛傝儕僜乕僗傪嬺傢傟傞偺偩偲悇應偟偰偄傞丅
揮憲懍搙傪恾帵偟偨偄儉僉偼丄Win95偵晬懏偟偰偔傞僱僢僩儚乕僋儌僯僞乕僣乕儖偺僀儞僗僩乕儖朄拞偺夝愢傪嶲徠偟偰丄僱僢僩儚乕僋儌僯僞乕僣乕儖傪僀儞僗僩乕儖偟偰傒偰梸偟偄丅MTU偺嵶岺偱丄揮憲懍搙偺愊暘抣偑夵慞偟偰偄傞條巕偑尒偊傞偩傠偆丅
MTU偺栤戣偵偮偄偰丄偝傜偵徻偟偔抦傝偨偄儉僉偼丄
偵忣曬偑懡偄偑丄塸岅偺忋丄撪梕偑傗傗屆偄偺偱丄杮擔偺撪梕埵偱廫暘偱偁傠偆偟丄Webmaster傕偙偺掱搙偟偐抦傜側偄丅懠偵傕儌僨儉偵嵶岺偟偰偁偲15%埲忋懍搙傪壱偖曽朄偑偁傞偑丄偦傟偼嬤偔曬崘偡傞梊掕偱偁傞丅
偛拲堄乮捛壛乯
傕偟Win95偵傛傞LAN偑偁傝偦偺僒乕僶乕偐傜ppp偱ISP偵愙懕偟偰偄傞応崌偼丄RWIN愝掕偵拲堄偑昁梫偩偲偄偆儊僀儖傪捀偄偨丅MTU偼ETHERNET偲ppp偼屄暿偵愝掕偱偒傞偑丄RWIN偼嫟捠偩偲尵偆丅偙偺偨傔丄RWIN傪MSS x 4偵愝掕偡傞偲丄ETHERNET偵懳偡傞RWIN偑夁彫偲側傝丄LAN偺僗儖乕僾僢僩偑掅壓偡傞偦偆偩丅ppp愙懕偲ISP偺娐嫬偵傕傛傞偟丄帺暘偱帋偟偨儚働偱偼側偄偑丄偙偺応崌偼RWIN偼Ethernet偵暪偣偰丂1460偺悢攞偵偟偨傎偆偑椙偄傛偆偵巚偆丅偛宱尡偺偁傞曽偼丄偛嫵帵偄偨偩偒偨偄丅
僟儊側儅僂僗偺僫僝(僱僢僩巎忋弶丄嶳杮幃儅僂僗夵憿朄儕傾儖價僨僆曇)偡偙偟峏怴傪偝傏偭偰偄偨傛偆偱丄怽偟栿側偄丅側傫偣崱廡偼俀夞傕嬤導傑偱擔婣傝弌挘偑偁偭偨偨傔偱偁傞丅埲慜偼DEC僴僀僲乕僩偲PHS偱儌乕僶僀儖峏怴偟偰偄偨偺偩偑丄嵟嬤偼僆僋儔擖傝偟偰偄傞丅傕偪傠傫丄Webmaster偑懩柊傪傓偝傏偭偰偄偨儚働偱偼側偄丅僱僢僩巎忋弶偺丄RealVideo偵傛傞儅僂僗夵憿朄傪價僨僆偱偍揱偊偡傞偨傔偵僣儊傪尋偄偱偄偨偺偱偁傞丅
悽偺拞偵偼丄偪傚偭偲偟偨墭傟偱偡偖億僀儞僞乕偺摦偒偑廰偔側傞儅僂僗偑偁傞丅杮擔偺僒儞僾儖偼丄FM/V偵偮偄偰偒偨丄巎忋傑傟側傞僟儊側儅僂僗偱丄撪晹儘乕儔傗儃乕儖傪憒彍偟偰傕偡偖摦偒偑廰偔側傞丅
偙偆偄偆偲偒偼丄儅僂僗偺儃乕儖傪屌掕偟偰偄傞僼僞傪僴僘偟偰婘偺忋偵抲偄偰傒偰丄摦嶌偑椙偔側傟偽僼僞偺愝寁偑埆偄偲敾抐偟偰椙偄丅
偙偺応崌丄僼僞偺寠傪巻儎僗儕偱戝偒偔偡傞偲娙扨偵夝寛偡傞丅憡摉寠傪戝偒偔偟偰傕丄儃乕儖偑棊偪側偗傟偽偐傑傢側偄丅偦偺條巕傪柍杁偵傕僱僢僩忋偱價僨僆偱徯夘偟傛偆丅
傑偢丄柍彏偺RealPlayerVer.5傪僟僂儞儘乕僪偟偰梸偟偄丅偙傟偱悽奅拞偺僯儏乕僗傗斣慻偺價僨僆偑丄28.8kbps儌僨儉偱廫暘妝偟傔傞偺偱惀旕姪傔偨偄丅Webmaster偼恖婥儃乕僇儖儐僯僢僩SPEED偺壧偲梮傝偑戝曄婥偵擖偭偨丅師偵丄
傪僋儕僢僋偟偰傒偰梸偟偄丅偆傑偔嵞惗偱偒偨偱偁傠偆偐丅偙偺夋憸偼丄MACNICA偺CUCMEE梡偺僇儔乕CCD僇儊儔乮儌僯僞乕偺忋偵偪傚傫偲忔偣傞儎僣丅幚偼NEC偺OEM)傪巊偭偰嶣塭偟偨丅MACNIA偺儁乕僕偵偼儘僋側僜僼僩偑忔偭偰偄側偄偑丄朸幮偺儂乕儉儁乕僕偵丄偙傟偺Video for Windows95 僪儔僀僶乕偲價僨僆僉儍僾僠儍乕僜僼僩偑儘僴偱懚嵼偡傞丅偙傟偱丄320x160x24bits偺夝憸搙偺枅昩俆僐儅偱嶣塭偟偨偲偙傠丄旕埑弅AVI僼傽僀儖偱19MB偵傕側偭偨丅偙傟傪丄Real Encorder ver5偱28.8Kbps梡偵僄儞僐乕僪偟偨偲偙傠丄側傫偲19MB偺僼傽僀儖偑70kB偲200暘偺侾埲壓偵側偭偨栿偱偁傞丅價僨僆傪傒偰傕傜偆偲傢偐傞偑丄攚宨偑摦偄偰偄側偄偺偑儈僜偱偁傞丅
偙偆偄偭偨價僨僆偺埑弅偺媄弍偵娭偟偰偼丄
傑偨丄壒惡偺埑弅媄弍偵娭偟偰偼丄
傪嶲徠偟偰偄偨偩偔偲椙偄偐傕抦傟側偄丅嵟屻偵戝彂偟偰偍偔偑丄崱夞偺僜僼僩椶偼偡傋偰儘僴偱偁傞丅儘僴偱嵟戝尷偺儊僨傿傾傪採嫙偡傞偺傕丄崅搙偺僄儞僕僯傾儕儞僌偺帓暔偱偁傞偲巚偆丅
嶳杮幃僶乕僠儍儖僒僂儞僪僔僗僥儉丂僼僅乕丂俹俠( PAT PEND.)偺僫僝
僀儞僩儘
嵟嬤偺僷僜僐儞偺僆乕僨傿僆娭學偵偼傂偳偄昳幙偺儌僲偑墶峴偟偰偄傞丅僒僂儞僪僇乕僪忋偺儊僀儞傾儞僾偑傂偳偄偙偲偼桳柤偱偁傞偑丄偩偐傜偲偄偭偰弌椡傪僆乕僨傿僆傾儞僾偵弌椡偡傞偲丄梋寁偵僷僜僐儞桼棃僲僀僘偑栚棫偭偰巇曽偑側偄丅
僒僂儞僪僇乕僪偺僲僀僘庢傝偵偮偄偰偼丄僗乕僷乕僗儘僢僩僗僞價儔僀僓乕傪嶲徠偄偨偩偔偲偟偰丄嶳杮幃僶乕僠儍儖僒僂儞僪僔僗僥儉(Virtual Sound System for PC PAT PEND.)偵傛偭偰椪応姶傪惙傝忋偘傞偙偲傪峫偊偨偄丅
尨棟
僗僺乕僇乕儅僩儕僢僋僗傪梡偄偨僒儔僂儞僪僒僂儞僪僔僗僥儉偵偮偄偰偼丄
偱偐側傝徻愢偟偨丅偙偺僔僗僥儉偼嬌傔偰桳岠偩偑丄僗僺乕僇乕傪係屄昁梫偲偡傞丅傕偪傠傫係屄巊偭偨偩偗偺岠壥偼偁偑傞傕偺偩偑丄壗偲偐偟偰慜僗僺乕僇乕俀屄偩偗偱僒儔僂儞僪岠壥傪摼傞偙偲偼偱偒側偄偱偁傠偆偐丅偙傟偑Webmaster偺偙偙侾擭偺壽戣偺堦偮偱偁偭偨丅
偪傑偨偵偼丄DSP傪梡偄偰俀屄偺僗僺乕僇乕偱椪応姶傪崅傔傞婡擻傪偮偗偨儎儅僴偺惢昳偑偁傝丄揦摢偱帋挳偟偨帠偑偁傞丅偟偐偟丄偦偺壒幙偼偲偰傕懴偊傜傟傞儌僲偱偼側偐偭偨丅巆嬁偵廃婜揑側惉暘偑忔偭偰偍傝丄傑傞偱揹攇忬懺偺埆偄帪偺実懷揹榖偺傛偆偵丄儚僂丄儚僽儖偑姶偠傜傟傞丅偙傫側壒傪暦偐偝傟傞儐乕僓乕傕垼傟偱偼偁傞偑丄妋偐偵椪応姶偼偁傞丅懠偺巗斕DSP僾儘僙僢僒乕傕偄偔偮偐偁傞偑丄Webmaster偺帹偱夝愅偟偨僔僇働偼偍偍傓偹師偺傛偆偵巚偊偨丅
1.抶墑偵傛傞巆嬁岠壥
椪応姶傪摼傞偨傔偺屆偄曽朄偱偁傞丅恀嬻娗傾儞僾偺帪戙偵傕丄儕僶乕僽儐僯僢僩偲偄偆丄僶僱傪巊偭偨僔儘儌僲偑偁偭偨偑丄偲偰傕HiFi乮偄傑傗巰岅乯偲偼尵偊側偐偭偨丅偙偺偨傔丄儗僐乕僪夛幮偱偼丄抧壓偵僐儞僋儕偱嶌偭偨巆嬁幒傪巊偭偰偄偨強傕偁偭偨丅
DSP偱偼丄帪娫偺抶傟偨怣崋傪壛嶼偡傞丅嬶懱揑偵偼僞乕僎僢僩偲偡傞儂乕儖偱抁偄僷儖僗惈偺壒傪弌偡丅偦偟偰媞惾偱偦傟傪婰榐偟丄偦偺揱払摿惈傪婰榐偡傞丅DSP偐傜弌椡偝傟傞壒偼丄尨壒偵揱払摿惈傪忔偠偨暔偱丄尨壒偲偺嵎偑巆嬁摿惈偵側傞丅偙偺尨棟偼実懷揹榖傗僀儞僞乕僱僢僩揹榖丄RealAudio側偳偱巊傢傟偰偄傞LPC偲偄偆曽幃偲尨棟揑偵摨條偱偁傞丅徻嵶偼偙偪傜偺LPC偺崁傪嶲徠偟偰梸偟偄丅
偙偺張棟偼娙扨偩丅偨偩丄僩儔儞僕僃儞僩摿惈偑傑偩楙傟偰側偄丅儂乕儖側偳偼壒偑屻曽偵岦偐偆偵偮傟偰偦偺揱払摿惈偑曄壔偡傞偺偩偑丄偦偺僔儏儈儗乕僔儑儞偑扨弮側偺偱丄掱搙偺崅偄恖偵偼懴偊傜傟側偄丅
2.埵憡憖嶌
偙傟偼尨棟揑偵偼僗僺乕僇乕儅僩儕僢僋僗偲摨偠偱偁傞丅塃(R)屻曽偵塃乕嵍乮R-L)偺惉暘傪弌椡偟丄嵍(L)屻曽偵嵍乕塃(L-R)偺惉暘傪弌椡偡傞傢偗偱偁傞丅偙傟偼扨側傞傾僫儘僌憖嶌偱傕壜擻偱偁傞偑丄DSP偱偁傟偽梕堈偩丅
儃乕僇儖傗掅壒偼摨埵憡惉暘偑懡偄偺偱丄扨弮偵嵎傪偲偭偨偺偱偼懪偪徚偝傟偰偟傑偆丅偦偙偱嵎怣崋偺掅偄壒傪僇僢僩偟丄偦傟偵抶墑傪慻傒崌傢偣傞偲椪応姶傪崅傔傞丅
偟偐偟丄巗斕偺DSP僾儘僙僢僒乕偺壒傪暦偄偰傕丄壗偲側偔帺慠側姶偠偑側偄丅偙偺庤偺怣崋憖嶌偵懳偡傞斸敾偼寢峔愄偐傜偁傝丄偨偭偨俀偮偺僠儍儞僱儖偺忣曬偐傜偦傟埲忋偺忣曬傪嶌傝弌偡偺偼晄壜擻偲偄偆愢傕崻嫮偄丅 偙偺偨傔丄夁嫀偵傕係僠儍儞僱儖棫懱壒嬁偲偄偆偺偼丄壗搙傕忲偟曉偝傟偨偵傕娭傢傜偢掕拝偟偰偄側偄傢偗偩丅Webmaster傕偐側傝帋峴嶖岆傪廳偹偰偒偨丅偟偐偟丄嵍塃偺嵎怣崋傪傛偔暦偔偲丄偦偙偵偼嬌傔偰帺慠側娐嫬壒傗巆嬁壒偑懡偔娷傑傟傞帠偑傢偐傞丅
偟偨偑偭偰丄嶳杮幃僶乕僠儍儖僒僂儞僪僔僗僥儉偱偼婛懚偺娐嫬壒傗巆嬁壒傪嵟戝尷偵惗偐偡偙偲傪栚揑偲偡傞丅帋挳傪廳偹偰
塃偺僗僺乕僇乕偵偼丂R-(L/3) 嵍偺僗僺乕僇乕偵偼丂L-(R/3)偺壒傪弌椡偡傞偙偲偲偟偨
3.幚嵺偺夞楬
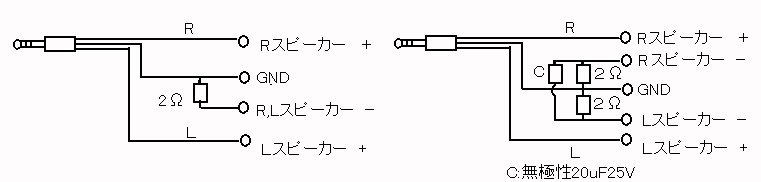 幚嵺偺夞楬傪恾帵偡傞丅偁傑傝偵傕娙扨偱崢偑敳偗傞偐傕抦傟側偄偑丄崅搙側僄儞僕僯傾儕儞僌偺嶻暔(徫)偱偁傞丅摦嶌尨棟偺愢柧偺昁梫傕柍偄偲巚偆丅
幚嵺偺夞楬傪恾帵偡傞丅偁傑傝偵傕娙扨偱崢偑敳偗傞偐傕抦傟側偄偑丄崅搙側僄儞僕僯傾儕儞僌偺嶻暔(徫)偱偁傞丅摦嶌尨棟偺愢柧偺昁梫傕柍偄偲巚偆丅
偄傠偄傠帋峴嶖岆偺寢壥丄晹昳偼侾屄偵傑偱廂懇偟偨丅掞峈抣偼丄摉慠僗僺乕僇乕偺僀儞僺乕僟儞僗偵傛偭偰堎側傞偑丄侾側偄偟俀僆乕儉掱搙偑椙偄傛偆偩丅掞峈傪戝偒偔偡傞傎偳壒応偑峀偑傝丄彫偝偔偡傞偲偨偩偺僗僥儗僆偵栠傞丅幚嵺偵俀僆乕儉偱惂嶌偟偰偍偗偽丄抂巕斅偵掞峈傪僷儔偵擖傟傞偙偲偵傛傝挷愡偱偒傞丅
幚偼摉弶塃偺傛偆側夞楬偩偭偨偺偩偑丄帋挳偺寢壥僐儞僨儞僒乕偼晄梫偱偁傞偙偲偑傢偐偭偨丅摉弶丄嵎怣崋偵傛傝掅壒偑尭彮偡傞偙偲傪婋湝偟偨偑丄掅壒偱偼忋徃偡傞僗僺乕僇乕偺僀儞僺乕僟儞僗偵斾傋掞峈抣偑憡懳揑偵掅壓偟嵎怣崋偼尭彮偡傞丅扽巁僈僗攔弌偺柺偐傜傕晹昳偼彮側偄偵尷傞丅
 幚憰偺嬶崌偼幨恀偺傛偆偵側傞丅晹昳偼僾儔僌偲揹慄丄掞峈堦屄偲僾僢僔儏宆僗僺乕僇乕抂巕偱偁傞丅僌儔僂儞僪偼僗乕僷乕僂乕僴乕愙懕偺偨傔偲丄掞峈偺挷愡梡偵抂巕斅偵傕弌偟偰偄傞丅偝傝偘側偔敳偗巭傔偵堦寢傃偟偨揹慄傗僔儏儕儞僋僠儏乕僽偺嬶崌偵丄Webmaster偺旤妛偑傢偐偭偰傕傜偊傞偱偁傠偆偐丠乮徫乯丅偙偺彫暔偼丄僒僂儞僪僽儔僗僞乕偺弌椡偵偄傠偄傠側僗僺乕僇乕傪偮側偄偩傝丄僗乕僷乕僂乕僴傪偮側偖偺偵曋棙偱丄堦偮偼嶌偭偰偍偔抣懪偪偑偁傞丅
幚憰偺嬶崌偼幨恀偺傛偆偵側傞丅晹昳偼僾儔僌偲揹慄丄掞峈堦屄偲僾僢僔儏宆僗僺乕僇乕抂巕偱偁傞丅僌儔僂儞僪偼僗乕僷乕僂乕僴乕愙懕偺偨傔偲丄掞峈偺挷愡梡偵抂巕斅偵傕弌偟偰偄傞丅偝傝偘側偔敳偗巭傔偵堦寢傃偟偨揹慄傗僔儏儕儞僋僠儏乕僽偺嬶崌偵丄Webmaster偺旤妛偑傢偐偭偰傕傜偊傞偱偁傠偆偐丠乮徫乯丅偙偺彫暔偼丄僒僂儞僪僽儔僗僞乕偺弌椡偵偄傠偄傠側僗僺乕僇乕傪偮側偄偩傝丄僗乕僷乕僂乕僴傪偮側偖偺偵曋棙偱丄堦偮偼嶌偭偰偍偔抣懪偪偑偁傞丅
偝偰丄弌棃忋偑傝偺壒偼帋偟偰傕傜偆偺偑堦斣偱偁傞偑丄晹昳偑彮側偄偩偗偁偭偰慺捈側壒偱偁傞丅偦傟偵壛偊丄壒応偑嵍塃偺僗僺乕僇乕偺奜懁偵傕帺慠偵峀偑傞丅偙偺偨傔丄僗僺乕僇乕偺愝抲応強偵廮擃惈偑弌偰偒偰丄偨偲偊嵍塃僗僺乕僇乕偺娫偑嫹偔偰傕峀偑傝偺偁傞壒応偑摼傜傟傞丅摉慠傂偢傒偼慡偔姶偠傜傟側偄丅
偙偆偟偰傒傞偲丄枹偩僆乕僨傿僆偵偼枹奐敪偺晹暘偑懡偔偁傞偙偲偑傢偐傞丅偄偐偵婛懚偺僆乕僨傿僆偑戃彫楬偵娮偭偰偄傞偐傪峫偊傞偺偵嵟揔側擔梛擔偺岺嶌偱偁傠偆丅
暯惉10擭宆愇桘僼傽儞僸乕僞乕偺僫僝乮婫愡抶傟偺僱僞曇乯嵟嬤帠柋嶨梡偑懡偄偣偄偐丄僷僜僐儞僱僞偑懡偔偰怽偟栿側偄丅偦傟偵偟偰傕丄傾儅僲僕儍僋側Webmaster偺応崌丄壗偲偐BENCH偱偼偄偔偮偱偳偭偪偑憗偄丄偲偐偁傝偒偨傝偺榖戣傪彂偔儚働偵偼峴偐側偄丅懝側惈奿偱偁傞丅
偙偺儁乕僕偼ReadmeJ偵搊榐偟偰偄傞偑丄僥僋僯僇儖側儁乕僕偲偟偰偼俁埵側偄偟係埵偁偨傝傪僂儘僂儘偟偰偄傞丅偝偡偑偵忋埵儁乕僕偼偳傟傕億儕僔乕偑偟偭偐傝偟偰丄杮摉偵挦傝側偐偭偨傝丄FAST偱FIRST側儁乕僕偩偭偨傝柤慜捠傝偱偁傞丅ReadmeJ偵搊榐偟偨偺偼嵟嬤偱丄偝傞儁乕僕偺儅僱偟偨偺偱偁傞偑丄搊榐儕僗僩傪尒偰傑偨傃偭偔傝偟偨丅傕偲傕偲巹偑椙偔峴偔儁乕僕偽偐傝偱偼柍偄偐丅峀偄傛偆偱嫹偄僱僢僩偱偁偭偨丅
乭寢峔僱僞廤傔偑戝曄偱偟傚偆丠乭偲儊僀儖傪捀偔丅崱偺偲偙傠丄Webmaster偼杮嬈偺僱僞偼堦愗巊偭偰偄側偄丅傕偟偦偺曽柺傪巊偊偽10擭暘丠偼偁傞偲巚偆偑丄姼偊偰擔忢偺暔傪戣嵽偵偡傞偙偲偵偟偰偄傞丅堛妛偺榖偑弌偩偟偨傜僱僞愗傟偲巚偭偰娫堘偄側偄丠
偝偰丄愇桘僼傽儞僸乕僞乕偵偮偄偰偼丄
偍擭嬍嫄曇(徫)丂愇桘僼傽儞僸乕僞乕戝尋媶偦偺俀乮儊僇僯僘儉曇乯
偍擭嬍嫄曇(徫)丂愇桘僼傽儞僸乕僞乕戝尋媶偦偺侾(旓梡曇乯
埲棃偱偁傞丅僼傽儞僸乕僞乕偲偄偆偺偼偄偐偵傕擔杮揑側惢昳偩丅昁偢俁帪娫偱愗傟偰姺婥偑昁梫側僴僘偩偑丄側偤偐墑挿儃僞儞偑偁偭偨傝偡傞丅愇桘側偺偱拝偄偨傝愗傟偨傝偡傞偲丄僯僆僀偑弌傞偟丄偄偮偐偼愇桘傪曗媼偟側偗傟偽偄偗側偄丅
偦偙偱儊乕僇乕偼摢傪峣傞丅僀儞僶乕僞乕僄傾僐儞偵偟偰傕偦偆偩偑丄傑偢僩儘壩偐傜嵟戝壩椡傑偱偺挷愡暆傪峀偔偡傞偺偑儈僜偱偁傞丅僩儘壩偑岠偗偽丄偄偪偄偪徚壩拝壩傪孞傝曉偡昁梫偑側偄偟丄愇桘偑挿帩偪偡傞丅
偙偺揰偱偼丄嵟嬤偼僩儘壩擱從偵桳棙側娵宍僶乕僫乕偵廂懇偟偮偮偁傞丅娵宍偩偲丄峣偭偰傕嬒堦偵壩偑傑傢傞偺偱丄埨掕偡傞丅嵟彫擻椡偼攧傟嬝偺2500Kcal僋儔僗偱丄僐儘僫偑430Kcal丄僒儞儓乕偑480Kcal丄搶幣偑480Kcal丄僫僔儑僫儖偑510Kcal偲側偭偰偄傞丅
娵宍僶乕僫乕偼偝傜偵俀宯摑偵暘偐傟傞丅愇桘傪嬻婥偱柖悂偒偡傞儀儞僠儏儕乕幃乮僐儘僫丄僒儞儓乕乯偲丄愱梡偺婥壔婍傪巊偆揹擬婥壔婍幃乮搶幣丄僫僔儑僫儖乯偱偁傞丅揹擬幃婥壔婍幃偼丄拝壩帪傗徚壩帪偺僐儞僩儘乕儖偑梕堈偱拝壩帪揹椡傕彫偝偄乮搶幣偱102W)偑丄婥壔婍偵忢帪捠揹偡傞偨傔偵擱從帪揹椡乮搶幣偱嵟彫43W)偑戝偒偄丅擱椏偺僞乕儖暘偵庛偄偺偱丄僞乕儖從偒愗傝婡擻偑昁梫偩丅
壗偐偲柍梡偵嬅傝惈側搶幣偼丄僩儘壩偑嬯庤側俀抜楍宆僶乕僫乕偐傜娵宍僶乕僫乕偵憤擖傟懼偊偟偨傛偆偩丅儔僀儞僼儘乕幃憲晽僼傽儞傕堦斒揑側幉棳僼傽儞傊偲丄傑偭偲偆側愝寁偵側偭偰棃偨丅
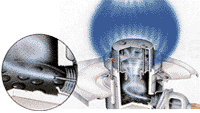 堦曽儀儞僠儏儕乕幃(恾偼僐儘僫傊偺儕儞僋乯偱偼丄拝壩帪偵僶乕僫乕働乕僗慡懱傪壛擬偡傞偺偱拝壩帪揹椡偑戝偒偄乮僐儘僫偱380W,僒儞儓乕偱600W)偑丄偄偭偨傫僶乕僫乕偑偁偨偨傑傟偽壛擬偑晄梫側偺偱擱從帪揹椡偑彫偝偄乮僐儘僫偱嵟彫12W丄僒儞儓乕偱13W)丅傑偨擱椏偺幙傪偁傑傝慖偽側偄丅
堦曽儀儞僠儏儕乕幃(恾偼僐儘僫傊偺儕儞僋乯偱偼丄拝壩帪偵僶乕僫乕働乕僗慡懱傪壛擬偡傞偺偱拝壩帪揹椡偑戝偒偄乮僐儘僫偱380W,僒儞儓乕偱600W)偑丄偄偭偨傫僶乕僫乕偑偁偨偨傑傟偽壛擬偑晄梫側偺偱擱從帪揹椡偑彫偝偄乮僐儘僫偱嵟彫12W丄僒儞儓乕偱13W)丅傑偨擱椏偺幙傪偁傑傝慖偽側偄丅
偙傟傜偺儊乕僇乕偼僶乕僫乕偺僨僓僀儞偵帺怣偑偁傞傜偟偔丄杦偳宍忬偵曄壔偑柍偄丅僒儞儓乕偼擱從梡僼傽儞偲僶乕僫乕偑寢崌偟偨旤偟偄僨僓僀儞偩偑丄慺偭婥側偄僨僓僀儞偺僐儘僫偺曽偑拝壩傕憗偔丄僯僆僀傕彮側偄偺偑晄巚媍偱偁傞丅
僫僔儑僫儖偼丄僽儔僔幃婥壔婍偲彫宆僶乕僫乕儀乕僗傪崌懱偝偣偨僔儘儌僲偵懼偊偰偒偨丅偪傚偆偳惈擻傕婥壔婍幃偲儀儞僠儏儕乕幃偺娫傪慱偭偰偄傞丅徚旓揹椡傕拝壩帪660W丄擱從帪嵟彫16W偲丄婥壔婍幃偱偁傝側偑傜儀儞僠儏儕乕幃偺徚旓僷僞乕儞偩丅
婎杮惈擻傛傝栚偵尒偊傞彫嵶岺偑摼堄側僫僔儑僫儖偼丄憲晽儖乕僶乕傪揹摦偵偟偰拝壩偡傞傑偱暵傔偰偍偔帠偲丄僾儔僠僫怗攠傪巇崬傓偙偲偱僯僆僀傪晻偠崬傔傞愝寁偩偑丄偦傟偱傕拝壩帪偵懠幮偺悢攞偺僯僆僀偑弌偰偄傞丅
娵宍僶乕僫乕恮塩埲奜偵偼丄擔棫偲僔儍乕僾偑巐妏宍僶乕僫乕偲揹擬婥壔婍傪梡偄偰偄傞丅偙偪傜傕嬅傝惈偺儊乕僇乕偱偁傞丅娵宍僶乕僫乕偵斾傋傞偲巐妏宍僶乕僫乕偼僩儘壩偱晄埨掕偵側傝傗偡偄丅偙偺偨傔擔棫偼儊僢僔儏傗僶乕僫乕傪僠僞儞偱嶌傝丄曐壏偲怗攠嶌梡偱埨掕壔偟偰偄傞丅傑偨僔儍乕僾偼僶乕僫乕偵僾儔僠僫傪僐乕僥傿儞僌偟丄怗攠嶌梡偱埨掕偝偣偰偄傞丅敀嬥僇僀儘偺尨棟偱偁傞丅
偙偺庤偺岺晇偱丄擔棫偼430Kcal丄僔儍乕僾偼490Kcal傑偱峣傟傞傛偆偵側偭偰偄傞偑丄婥壔婍偺偨傔擱從帪傕揹椡乮擔棫偱52W掱搙嬺偭偰偄傞丅
埶慠偲偟偰撈帺偺楍宆僶乕僫乕偲丄擱從僼傽儞傪徣棯偟偰憲晽僼傽儞偱偡傋偰傪傑偐側偆娙慺側峔憿偑僟僀僯僠偱偁傝丄偙傟傕嵟嬤戝偒側夵曄偼柍偄丅傑偨丄嬃偔傎偳娙扨側峔憿偺儗乕僓乕僶乕僫乕偺僩儓僗僩乕僽傕偁傑傝曄壔偑柍偄偺偱丄徻嵶偼棯偡傞丅
偝偰僞儞僋偼戝宆壔偟偰偄傞丅攧傟嬝偺惢昳偱偼7.2儕僢僩儖偵払偟偰偄傞丅僞儞僋偑戝偒偄偲曗媼夞悢偑尭傞偑廳偔側傞丅懳嶔偲偟偰戝偒側庢偭庤傪拝偗傞偺偑棳峴偟偰偄傞丅
偟偐偟側偑傜愇桘曗媼偺搙偵丄埶慠偲偟偰愇桘偵擥傟偨僞儞僋偺愷偵偝傢傜側偗傟偽側傜側偄丅傑偨丄掲傔嬶崌傕僼傽僕乕偱偁傞丅偄偔偮偐偺儊乕僇乕偼愷傪備傞傔傞僑儉傪僆儅働偵偟偰偄傞埲奜丄偝偟偨傞恑曕偑側偄丅
 偙偺揰偱埑搢揑偵桪傟偰偄傞偺偼丄慜擭摨條偺僐儘僫偺傛偛傟傑愷偩偲巚偆丅変偑壠偱傕偙傟傪巊偭偰偄傞偑丄婋湝偟偨屘忈傗桘楻傟偼柍偄丅枮僞儞僽僓乕傕柺敀偄丅
偙偺揰偱埑搢揑偵桪傟偰偄傞偺偼丄慜擭摨條偺僐儘僫偺傛偛傟傑愷偩偲巚偆丅変偑壠偱傕偙傟傪巊偭偰偄傞偑丄婋湝偟偨屘忈傗桘楻傟偼柍偄丅枮僞儞僽僓乕傕柺敀偄丅
庒姳偺夵椙傪尒偣偰偄傞偺偼僒儞儓乕偱偁傝丄媼桘柤恖偲偄偆柤慜偱僶儓僱僢僩幃偺愷偵側偭偰偄傞偑丄巊偄彑庤偼傛偛傟傑愷偵媦偽側偄丅傕偲傕偲僒儞儓乕偼愷偺捈宎偑彫偝偔丄埖偄偵偔偐偭偨丅
栤戣側偺偼丄彫嵶岺偑摼堄側僫僔儑僫儖傕丄嬅傝惈偺搶幣傕丄僞儞僋偺愷偵偮偄偰偼夵椙偑尒傜傟偢丄庤敳偐傝傪曻抲偟偰偄傞帠偱偁傞丅摿偵丄彫嵶岺傪楳偡傞僫僔儑僫儖偼丄偦偺儗僝儞僨乕僩儖傪栤傢傟偰偄傞偲巚偆偑丅
偲偄偆傢偗偱丄愇桘僼傽儞僸乕僞乕偵偮偄偰偼丄擱從惈擻偱傕曗媼偱傕埶慠僐儘僫偑堦曕儕乕僪偟偰偄傞傛偆偵巚偆丅暯惉侾侾擭儌僨儖偼偳偆側傞偩傠偆偐丅
宨婥掅柪偺偍傝丄昻朢側Webmaster偺傛偆偵丄僄傾僐儞傪巭傔偰僼傽儞僸乕僞乕偵偡傞壠掚偑憹偊傞偐傕抦傟側偄丅変偑壠偱偼埲慜彂偄偨傛偆偵丄慡幒揹婥偺僄傾僐儞偐傜僼傽儞僸乕僞乕偵揮姺偟偨丅偍偐偘偱尩姦帪傕夣揔偵側偭偨忋偵丄嵟戝寧\20000埲忋偺愡栺偵側偭偰偄傞丅
偍偙偲傢傝丅忋婰僒儞僾儖偵俵旽偑柍偄偲偍偙傜傟偦偆偩偑丄幚暔傪娤嶡偡傞僠儍儞僗偑柍偐偭偨偩偗偱偁傝丄懠堄偼柍偄丅
嵟弶偵栠傞
March丂3
俴俀僉儍僢僔儏桳岠偱儀儞僠儅乕僋偑抶偔側傞CPU偺僫僝乮6x86MX偲P55C偺堘偄傪扵傞曇乯
埲慜丄儀儞僠儅乕僋偺僐乕僪僒僀僘偵傛偭偰俴俀僉儍僢僔儏偺岠壥偑堎側傞帠偵偮偄偰丄
僷僜僐儞BENCHMARK偲L2僉儍僢僔儏桳柍偺娭學偺僫僝乮杮朚弶丄Webmaster熡恎憤廤曇乯
偱曬崘偟偨丅傑偨儊儌儕乕揮憲擻椡偵懳偡傞俴俀僉儍僢僔儏偺塭嬁傪丄
僷僜僐儞BENCHMARK偲L2僉儍僢僔儏桳柍偺娭學偺僫僝乮CPU偺僉儍僢僔儏埶懚惈僌儔僼偺偍傑偗曇乯
偱曬崘偟偨丅
崱夞偼P55C偱柺敀偄偙偲偵婥晅偄偨丅俴俀僉儍僢僔儏桳岠偱媡偵抶偔側傞儀儞僠儅乕僋偑偁傞丅傑偨丄P55C偲6x86MX偱偼丄L2僉儍僢僔儏桳柍偵傛傞儀儞僠儅乕僋偺傆傞傑偄偑堎側傞帠傕暘偐偭偨丅
偙偆偟偰傒傞偲丄偦傕偦傕摿掕偺BENCHMARK偺傒偱堎側傞CPU偺桪楎傪榑媍偡傞帠偺嬻偟偝偑幚姶偝傟傞丅傑偨壗傪斀塮偟偰偄傞偐夝傜側偄曄側BENCH傕偁傞丅
應掕忦審
P55C偼75MHzX2.5丄VPX僠僢僾僙僢僩丄Edo32MB,Virge/DX偱偁傞丅6x86MX偼丄SiS5598僠僢僾僙僢僩丄Edo32MB丄SiS撪憼VGA偱偁傞丅
HDBENCH偺応崌
P55C偱傕6x86MX偱傕丄L2僉儍僢僔儏偺桳柍偵傛傞惉愌嵎偼1%埲壓偱偁傞丅僐乕僪僒僀僘偼281kB偩偑丄偦傟偧傟偺應掕崁栚偺儖乕僠儞偼丄P55C偺32kB偵擺傑傞僒僀僘偱偁傞偙偲偑梊憐偝傟傞丅
Super-PI偺応崌
6x86MX偼L2僉儍僢僔儏柍偟偱寁嶼擻椡偼59%偵掅壓偟偨丅堦曽P55C偱偼75%偵掅壓偟偨丅僐乕僪僒僀僘偑104KB側偺偱丄偳偪傜偺CPU偱傕僐乕僪偼俴俀僉儍僢僔儏忋偵忔傞偼偢偱偁傞丅
尨場偲偟偰丄6x86MX偱偼丄偙偪傜偺僌儔僼偺捠傝丄128kB晅嬤偺L2僉儍僢僔儏偺岠壥偑P55C傛傝崅偄偨傔丄L2僉儍僢僔儏柍偟偺塭嬁偑戝偒偄偐傜偱偁傠偆丅
WINBENCH98偺応崌
傑偢CPUMARK32偩偑丄僐乕僪僒僀僘偑161kB偲丄L2僉儍僢僔儏偺岠棪偺崅偄晅嬤偵偁傞偲巚傢傟傞丅
6x86MX偱偼L2僉儍僢僔儏柍偟偱寁嶼擻椡偑45%傊偲戝偒偔掅壓偟偨丅偙傟偼偁傜備傞BENCH偺拞偱堦斣戝偒側掅壓偱偁傞丅堦曽丄P55C偱偼73%偵掅壓偟偨偑丄偙偺曽偑幚悽奅傾僾儕傗懠偺BENCH偲傕嫟捠惈偑崅偄丅
CPUMARK32偑壗傪寁嶼偟偰偄傞偺偐晄柧偩偑丄偊傜偔帪娫偑偐偐傞偲偙傠傪尒傞偲丄偄傠偄傠側嵄枛側僐乕僪傑偱娷傔偰丄幚悽奅傾僾儕偲偐偗棧傟偨曄側寁嶼傪偟偰偄傞偲巚偆丅偙傟偑偄傠偄傠側嶨帍偱巊傢傟偰偄傞偙偲傪峫偊傞偲傔傑偄偑婲偙傝偦偆偱偁傞丅
FPUmark偼偝傜偵曄偱偁傞丅6x86MX偱偼L2僉儍僢僔儏柍偟偱寁嶼擻椡偼98%偲丄杦偳嵎偑柍偄丅偙傟偼僐乕僪僒僀僘偑79kB偲彫偝偄偨傔丄庡梫晹暘偑6x86MX偺64kB偺L1僉儍僢僔儏偵擺傑傞偨傔偱偁傠偆丅
嬃偔偙偲偵丄P55C偱偼L2僉儍僢僔儏柍偟偱寁嶼擻椡偼102%偲媡偵懍偔側傞丅棟桼偩偑丄Webmaster偺悇應偵傛傞偲丄僐乕僪僒僀僘偑P55C偺32kB偺L1僉儍僢僔儏偐傜傢偢偐偵偁傆傟傞偨傔儈僗僸僢僩偟丄儁僫儖僥傿乕傪怘偭偰偟傑偆偺偱偁傠偆丅
杮棃偼L2僉儍僢僔儏偑L1僉儍僢僔儏傪曗嫮偡傞僴僘偱偁傞偑丄媡偵儈僗僸僢僩傪憹傗偟偰儁僫儖僥傿乕傪彆挿偟偰偄傞傛偆偱偁傞丅偐側傝僉儍僢僔儏傾儖僑儕僘儉偑僾傾側偺偱側偐傠偆偐丅
Intel Media Benchmark偺応崌
6x86MX偱偼L2僉儍僢僔儏柍偟偵傛傞惉愌掅壓偼丄Total偱栺86%偱偁傞丅屄乆偵尒傞偲丄僨乕僞僒僀僘偑12MB偲戝偒偄Image偱偼97%丄3.2MB偺Audio偱偼91%偲L2僉儍僢僔儏偺塭嬁偑彫偝偄丅
P55C偱偼L2僉儍僢僔儏柍偟偵傛傞惉愌掅壓偼丄Total偱94%偲彫偝偄丅6x86MX偲堎側傝丄Image偱偼99%偲掅壓偑彫偝偄偺偵丄Audio偱偼92%偲傗傗戝偒偔偱傞丅偁傞偄偼價僨僆僇乕僪偺塭嬁傕偁傞偐傕抦傟側偄丅
偄偢傟偵偟偰傕丄杮摉偺CPU僷儚乕傪昁梫偲偡傞丄僐乕僪傗僨乕僞偺僒僀僘偺戝偒側儅儖僠儊僨傿傾偱偼丄L2僉儍僢僔儏偼偁傑傝岠偐側偄丅P55C偼6x86MX傛傝偝傜偵L2僉儍僢僔儏偺岠壥偑朢偟偄丅傑偨丄CPU偵傛偭偰張棟偺摼堄丄晄摼堄偑偁傞傛偆偩丅
Wintune98偺応崌
傑偢Dhrystone偱偁傞偑丄6x86MX偺応崌偵偼L2僉儍僢僔儏柍偟偱100%偲丄L2僉儍僢僔儏偺岠壥偼傑偭偨偔柍偄丅偙傟偼僐乕僪僒僀僘偑53kB偲彫偝偔丄L1僉儍僢僔儏偵忔偭偰偟傑偆偐傜偱偁傠偆丅
堦曽丄P55C偱偼95%偺掅壓偲丄6x86MX傛傝塭嬁偑傗傗戝偒偄丅傗偼傝Dhrystone偺戝晹暘偼L1僉儍僢僔儏偵忔傞偑丄L1僉儍僢僔儏偑6x86MX傛傝彫偝偄偨傔丄庒姳儈僗僸僢僩偟偰偄傞偲峫偊傜傟傞丅
師偵Whetstone偼丄6x86MX偱偼L2僉儍僢僔儏柍偟偱98%偵掅壓偲杦偳塭嬁偼柍偄丅堦曽P55C偱偼L2僉儍僢僔儏柍偟偱79%偵掅壓偲塭嬁偑戝偒偄丅偙傟傕丄Whetstone偺堦晹偼P55C偺L1僉儍僢僔儏偐傜偁傆傟丄偐側傝儈僗僸僢僩偟偰偄傞帠傪帵偡丅
儊儌儕乕揮憲懍搙偲L2僉儍僢僔儏桳柍偺娭學偼偡偱偵帵偟偨偺偱丄偙偙偱偼怗傟側偄丅
寢榑
偙偆傗偭偰斾傋偰傒傞偲丄CPU偺桪楎傪扨弮側BENCH偱斾傋傞偙偲偺擄偟偝偑幚姶偝傟傞丅CPU偺僐傾惈擻偩偗偱側偔丄僉儍僢僔儏偺僒僀僘傗傾儖僑儕僘儉偺惈擻偑偐側傝塭嬁偟偰偔傞丅偙偆偄偆斾妑偼丄偁傞偄偼傑偭偨偔堄枴偑柍偄丄偲尵偆恖偑偄偰傕晄巚媍偱偼柍偄丅
摿偵栤戣側偺偼丄懡偔偺嶨帍偑嵦梡偟偰偄傞CPUmark32偲FPUmark偺懨摉惈偺偱偁傞丅偙傟傜偺悢帤偼丄懡偔偺幚悽奅偺傾僾儕偺惉愌傗懠偺BENCH偺寢壥偲傕偐偗棧傟偰偄傞丅
偙傟偑尃埿偁傞嶨帍桼棃側偺偱僞僠偑埆偄丅Webmaster偼丄偼偭偒傝尵偊偽帪娫偑偐偐傞傢傝偵懨摉惈偵媈栤偺巆傞BENCH偩偲巚偆丅
摿偵柺敀偄偺偼丄FPUmark偱丄P55C偱偼L2僉儍僢僔儏柍偟偺曽偑懍偔側傞丅P55C偼L1僉儍僢僔儏偺儈僗僸僢僩偺儁僫儖僥傿乕偑戝偒偔丄僉儍僢僔儏惂屼傾儖僑儕僘儉傕忋摍偱側偄報徾偑偁傞丅
Webmaster偺庤尦偵傛偣傜傟偨儊僀儖偵傛傟偽丄Write偵偍偄偰6x86MX偲P55c偵偼傾儖僑儕僘儉偺堘偄偑偁傞偦偆偩丅
P55C偺僉儍僢僔儏傾儖僑儕僘儉偼丄noallocate-on-write偲屇偽傟傞傕偺偱丄彂偒崬傓傾僪儗僗偑L1僉儍僢僔儏忋偵柍偄応崌偼僠僢僾奜偵捈愙彂偒弌偝傟丄偦傟偼L1僉儍僢僔儏偵偡偖偵偼斀塮偝傟側偄丅
6x86MX偺応崌偼丄allocate-on-write偲屇偽傟丄彂偒崬傓傾僪儗僗L1僉儍僢僔儏忋偵柍偄応崌偼丄僠僢僾奜偐傜L1偵偄偭偨傫撉傒崬傫偩忋偱L1忋偵彂偒崬傑傟傞丅彂偒崬傑傟偨撪梕偼丄CPU偑儊儌儕乕僶僗傪曻偟偨帪偵僠僢僾奜偵writeback偝傟傞丅
廬偭偰丄師夞彂偒崬傑傟傞偲偒偵丄偦偺傾僪儗僗偑偡偱偵L1僉儍僢僔儏忋偵偁傝僸僢僩偡傞壜擻惈偑崅偔側傞丅偙傟偑丄write擻椡偑崅偄棟桼偱偁傞偲尵偆丅
偙偆偟偰傒傞偲丄6x86Mx偼側偐側偐柺敀偄CPU偱偁傞偙偲偑暘偐傞丅傑偢摨堦撪晹僋儘僢僋偱偼6x86MX偑堦斣張棟擻椡偑崅偔丄Pentium-Pro傗Pentium-II傪忋夞偭偰偄傞丅僉儍僢僔儏偺擻椡傕32kB偺6x86L偱偝偊P55C傛傝崅偄傛偆偩丅K6偵偮偄偰傕挷傋傞梊掕偩偑丄傑偩挷払偱偒偰側偄丅
幚嵺偵傾僾儕傪巊偭偰偄傞偲丄6x86MX(66x2)偼PR儗僀僥傿儞僌偑摨偠P55C乮166MHz乯傛傝懍偄傛偆側婥偑偡傞丅崱屻僾儘僙僗偑夵慞偟偰撪晹僋儘僢僋偑忋徃偡傞偲丄P55C偳偙傠偐崱屻搊応偑梊憐偝傟傞Pentium-II偺僐傾傪梡偄偨socket7僞僀僾偺CPU傕夃傓傎偳偩丅
埲慜偺屳姺惈傗敪擬偺昡敾偑旜傪傂偄偨偺偐丄戝儊乕僇乕偺嵦梡偑彮側偄偑丄1000僪儖僋儔僗偱偼MediaGX偺嵦梡偑憹偊偰偄傞偙偲偐傜丄崱屻偼忬嫷偑曄傢傞偐傕抦傟側偄丅
偄偢傟偵偟偰傕丄BENCH偼偁偔傑偱傕BENCH偱偁傝丄寢嬊儐乕僓乕偺報徾偑偡傋偰偱偁傞偲傕尵偊傞丅Webmaster偺儌僢僩乕偼丄
TRUST YOUR FEELING!
MAY THE CPU FORCE BE WITH YOU!
偱偁傞丅
嵟弶偵栠傞
March丂1
嶳杮幃僗乕僷乕僗儘僢僩僗僞價儔僀僓乕偺僫僝(晽悈妛揑僲僀僘媦傃揹埑崀壓崻愨曇乯
棃傞傋偒崅僶僗僋儘僢僋帪戙傪寎偊丄Webmaster傕婥偑堷偒掲傑傞巚偄偱偁傞丅埲慜偐傜婥晅偄偰偄偨偑丄崅僶僗僋儘僢僋偱偼丄摨偠働乕僗偵摨偠儅僓乕儃乕僪偲僇乕僪椶傪慻傫偱傕摨偠埨掕惈傪傕偮偲偼尷傜側偄丄偲偄偆偙偲偱偁傞丅幚憰曽朄偑岠偄偰偔傞丅
愭擔丄僷僜僐儞偺揹尮僼傽儞偺壒偑丄僷僜僐儞偑Doze儌乕僪偵擖傞搙偵丄傢偢偐偵掅偔側傞偙偲偵婥偯偄偨丅Doze儌乕僪偵擖傞偲丄CPU僋儘僢僋偑栺30%偵掅尭偝傟傞偨傔偵CPU傊偺揹棳偑尭傝丄揹尮偲CPU偺娫偺揹埑崀壓傕尭傞丅偙偺偨傔AT揹尮偺晧婣娨夞楬偑摥偒丄揹尮偺揹埑偑傢偢偐偵壓偑傞丅偲偄偆偙偲偼丄儅僓乕偱偐側傝偺揹埑崀壓偑惗偠偰偄傞帠偵側傞丅
僷僜僐儞偺儅僓乕偼懡憌婎斅偱丄僂儔丄僆儌僥偺攝慄埲奜偵僌儔僂儞僪傗揹尮偺憌偑偁傞丅憌偼嬌敄偺摵敁惢偱丄柺愊偑偁傞偺偱斾妑揑揹婥掞峈偼掅偄偑丄CPU偑10A嬤偔傕徚旓偡傞偨傔偵婎斅撪偱揹埑崀壓傪惗偠傞丅婎斅撪偺僌儔僂儞僪揹埵偑堦掕偱柍偄帠偼丄晽悈妛揑偵栤戣偑偁傝丄傑偨崅偄僶僗僋儘僢僋偱偺埨掕摦嶌偺揋偱偁傞丅崱夞偼丄僷僜僐儞晽悈妛揑偵僲僀僘傪傕夝寛偡傞偺偱偁傞丅
偙偺偙偲偼僗儘僢僩偵嵎偡僇乕僪椶偵傕埆塭嬁傪媦傏偡丅儅僓乕偲働乕僗偑揹婥揑偵摍揹埵偱愙抧偝傟偰偄側偄偲丄揹尮偐傜揹棳偑儅僓乕偐傜僇乕僪椶傪宱偰丄働乕僗偵棳傟傞偙偲偵側傞丅偙偺偨傔丄僇乕僪椶偵儅僓乕傗懠偺僇乕僪偺捈棳惉暘傗僲僀僘偑棳傟崬傓帠偵側傞丅嵟嬤偱偼CPU傑傢傝偺僗僀僢僠儞僌儗僊儏儗乕僞乕偺偨傔丄偝傜偵僲僀僘娐嫬偑埆壔偟偰偄傞丅
摿偵儌僨儉傗僒僂儞僪僇乕僪偺傛偆偵丄傾僫儘僌夞楬偵僲僀僘偑忔傞偙偲栤戣偵側傞丅SCSI僇乕僪椶偱傕丄僲僀僘儅乕僕儞偑尭傝僞乕儈僫儖揹埑偑晄埨掕偵側傞偲丄岆摦嶌偺尨場偲側傞丅
偵傕偐偐傢傜偢丄儅僓乕偼僐僗僩僟僂儞偺偨傔丄働儈僐儞傗僲僀僘僼傿儖僞乕偺椶偼丄嬌尷傑偱愡栺偝傟偰偄傞丅儅僓乕傪椙偔尒傞偲丄幚憰偝傟偰偄側偄働儈僐儞偺僷僞乕儞偑懡偔偁傞丅
幚嵺丄偙偺儅僔儞偱偼丄僒僂儞僪僽儔僗僞乕偵僿僢僪儂儞傪偮側偖偲僲僀僘偑傢偢偐偵暦偙偊偰偄偨丅儅僓乕偼嬥懏惢僗僞儞僪僫僢僩俀屄偲僫僀儘儞僫僢僩椶偱働乕僗偵屌掕偝傟偰偄偨丅帋偟偵俇僇強慡晹傪嬥懏惢僗僞儞僪僫僢僩偱働乕僗偵偑偭偪傝屌掕偟偨偲偙傠揹埑崀壓偑尭彮偟丄揹尮僼傽儞偺壒傕杦偳曄壔偟側偔側偭偨偟丄僒僂儞僪偺僲僀僘傕尭偭偨丅
偙偺傛偆偵丄儅僓乕偑崅僋儘僢僋偱晄埨掕偺応崌偼丄屌掕曽朄傪尒捈偡昁梫偑偁傞丅偦偺嵺丄昁偢儅僓乕偺僂儔偺嬥懏僗僞儞僪僫僢僩偵愙偡傞柺偑僌儔僂儞僪偵側偭偰偄傞偐偳偆偐妋擣偡傞丅傑偨僆儌僥偺僱僕偑廃埻偺夞楬偵愙怗偟偦偆側応崌偼丄僱僕偵愨墢儚僢僔儍乕(拑怓乯傪巊偆丅
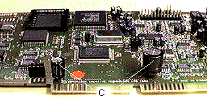 偦傟偱傕丄僒僂儞僪僇乕僪偵僲僀僘偑忔偭偨傝丄偁傞偄偼價僨僆僇乕僪偵幦柾條偑忔傞応崌偵偍偡偡傔偟偨偄偺偑丄嶳杮幃僗乕僷乕僗儘僢僩僗僞價儔僀僓乕(PAT
PEND.)偱偁傞丅
偦傟偱傕丄僒僂儞僪僇乕僪偵僲僀僘偑忔偭偨傝丄偁傞偄偼價僨僆僇乕僪偵幦柾條偑忔傞応崌偵偍偡偡傔偟偨偄偺偑丄嶳杮幃僗乕僷乕僗儘僢僩僗僞價儔僀僓乕(PAT
PEND.)偱偁傞丅
僇乕僪僗儘僢僩偺揹尮儔僀儞傪埨掕壔偝偣傞偺偑尨棟偱偁傞丅ISA僇乕僪偼丄愝寁偺晄旛偵傛傝揹尮傗僌儔僂儞僪儔僀儞偑彮側偄丅偙偺揰丄PC9800偺俠僶僗偺曽偑丄偼傞偐偵椙偔偱偒偰偄傞丅
偙偺偨傔丄僗儘僢僩廃傝偺僲僀僘儅乕僕儞偑彮側偄丅僗儘僢僩偵僇乕僪傪偝偡弴斣偵傛偭偰僲僀僘儅乕僕儞偑堎側偭偨傝偡傞丅杮棃側傜丄儅僓乕儃乕僪偵捈愙僲僀僘懳嶔偺僐儞僨儞僒乕椶傪捛壛偡傞偺偩偑丄儅僓乕傪偼偢偡偺偼柺搢偩丅
偦偙偱丄揹尮埨掕壔偺僔僇働傪壛偊偨僗乕僷乕僗儘僢僩僗僞價儔僀僓乕僇乕僪傪嵎偡偙偲偵傛傝丄僗儘僢僩傪埨掕壔偝偣傞傢偗偩丅僇乕僪椶偺僲僀僘懳嶔偵側傞偩偗偱偼側偔丄傂偄偰偼儅僓乕儃乕僪偺摦嶌帺懱傪埨掕壔偝偣傞丅幨恀偱帵偟偰偄傞偺偑丄捛壛偝傟偨働儈僐儞偱偁傞丅
ISA僇乕僪偱偼丄僂儔柺偺嬥嬶傛傝偺曽偐傜GND丄傂偲偮偍偄偰+5V偲側偭偰偄傞丅傑偨俋斣栚偑+12V偱侾侽斣栚偑GND偱偁傞丅傑偨29斣栚偑+5V偱偁傝31斣栚偑GND丅偝傜偵16價僢僩懁偱偼丄嬥嬶偐傜堦斣墦偄偺偑GND偱丄偦傟偐傜堦偮偍偄偰慜偑+5V偱偁傞丅
偙偙偺偲偙傠傪儚僓偲徻偟偔彂偄偰側偄偺偼丄僔儘僂僩傪攔彍偡傞偨傔偱偁傞丅庤尦偵妋擣偡傞帒椏偺柍偄儉僉傗丄彂偄偰偁傞偙偲偑壗偺偙偲偐傢偐傜側偄儉僉偼丄庤傪壛偊傞偺傪偁偒傜傔偰梸偟偄丅傑偨丄崱夞偺晹昳偼僄僐儘僕乕偲儕僒僀僋儖偺娤揰偐傜丄
偺僇乕僪偐傜挷払偟偨丅偙偺偨傔丄梋寁側扽巁僈僗偼嵟彫尷偟偐徚旓偟偰偄側偄丅怴偨偵挷払偡傞偺偱偁傟偽丄懷偑嬥怓偺崅媺僆乕僨傿僆梡働儈僐儞偑朷傑偟偄丅偙傟傜偼崅偄廃攇悢偺僲僀僘偺媧廂擻椡偵桪傟偰偄傞丅價僨僆婡婍偱傕廳梫側晹暘偵巊傢傟偰偄偨傝偡傞丅
偙傟傜偺愙揰偐傜僇乕僪偺僷僞乕儞傪偨偖傞偲丄働儈僐儞傕偟偔偼僞儞僞儖僐儞偑偁傞丅梕検偼偩偄偨偄16V10uF掱搙偺帠偑懡偄丅偙傟偵働儈僐儞偱偁傟偽16V500uF埵傪僷儔偵敿揷僣働偡傞丅巇忋偑傝偼幨恀傪嶲峫偵偟偰梸偟偄丅攚偑崅偔側傞偲椙偔側偄丅傑偨丄僒僂儞僪僇乕僪偺応崌偼+5V偩偗偱側偔丄+12V偵傕懳嶔偡傞偲岠壥揑偱偁傞丅
働儈僐儞偺梕検偱偁傞偑丄戝偒偡偓傞偲僗儘僢僩偺愙揰偑捝傓偟丄彮側偄偲岠壥偑柍偄丅ISA偺僗儘僢僩偼愙揰梕検偑戝偒偄偺偱丄500uF偁偨傝偑揔摉偺傛偆偩丅PCI僇乕僪偱傕摨條偺懳嶔偑峴偊傞偑丄ISA偺曽偼愙揰梕検偑戝偒偄偺偱岠壥揑偱偁傞丅
側偍丄働儈僐儞偺偳偭偪偑儅僀僫僗偐傢偐傜側偄儉僉傗丄幚憰曽朄偑傢偐傜側偄儉僉偼丄偙偺榖偺帠偼偡偭偐傝朰傟偰梸偟偄丅悽偺拞偵偼丄抦傜側偄曽偑椙偄偙偲傕懡偄偺偱偁傞丅
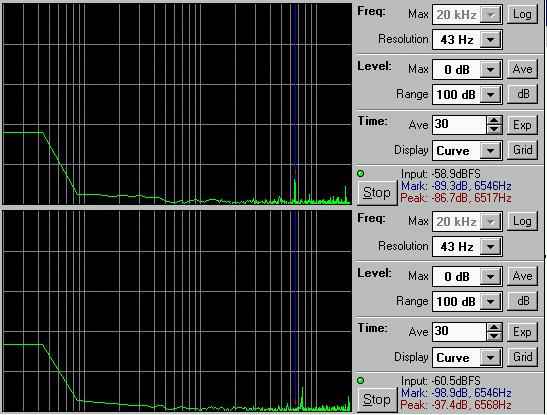
偙傟偼丄僗乕僷乕僗儘僢僩僗僞價儔僀僓乕僇乕僪懳嶔慜屻偺僒僂儞僪僽儔僗僞乕16偺僲僀僘僼儘傾傪FFT夝愅偟偨傕偺偱偁傞丅偛傜傫偺傛偆偵丄僲僀僘僼儘傾傕僲僀僘僺乕僋傕夵慞偟偰偍傝丄僒僂儞僪僇乕僪偲偟偰偼偐側傝偺僲僀僘儗儀儖傪払惉偟偰偄傞丅
儅僓乕儃乕僪偺僱僕巭傔懳嶔偲丄嶳杮幃僗乕僷乕僗儘僢僩僗僞價儔僀僓乕僇乕僪偵傛傝丄埨暔僒僂儞僪僽儔僗僞乕16偺壒幙偼寑揑偵夵慞偟丄僲僀僘偼僿僢僪儂儞偱傕姶抦偱偒側偔側偭偨丅
榁攌怱僐乕僫乕
偙偺夵憿偼娙扨偱丄僇乕僪偺摦嶌偑椙偔側傞偙偲偑偁偭偰傕埆偔側傞偙偲偼奆柍偺僴僘偱偁傞偑丄偁傞掱搙偺僷僜僐儞偲揹婥岺嶌偺抦幆傪梫偡傞偺偱丄彂偄偰偁傞偙偲偑夝傜側偄応崌偼丄偟偽偟挷傋偰偐傜帋偟偰梸偟偄丅
偙偺晽悈妛揑側夵憿偼丄僄僉僗僷乕僩偺傒偵偟偐偡偡傔傜側偄偺偑巆擮偱偁傞丅
嵟弶偵栠傞
嵟弶偵栠傞
E-mail偽乕偪傖傞帹旲堲岮壢傊偺儕儞僋
 Return to Home Page 儂乕儉儁乕僕偵栠傞
Return to Home Page 儂乕儉儁乕僕偵栠傞

{kind=link}